Lección 14 Contrastes de hipótesis
En muchas situaciones, queremos tomar una decisión sobre si podemos aceptar o rechazar una hipótesis relativa al valor de un parámetro en una o varias poblaciones, y para tomar esta decisión, nos basamos en los datos de una muestra. Por ejemplo:
Queremos saber si una moneda está trucada a favor de cara.
Para decidirlo, la lanzamos varias veces y contamos cuántas caras salen.
Queremos decidir si un tratamiento nuevo A es más efectivo que el tratamiento anterior B en la curación de una enfermedad X.
Para decidirlo, llevamos a cabo un ensayo clínico, tratando con A un grupo de enfermos y con B otro grupo de enfermos, y comparamos la tasa de curación de los tratamientos sobre estos dos grupos.
El método estadístico que se usa para aceptar o rechazar una hipótesis a partir de los datos de una muestra recibe el nombre de contraste de hipótesis.
14.1 Hipótesis nula y alternativa
En un contraste de hipótesis, se comparan siempre dos hipótesis alternativas: la hipótesis nula \(H_{0}\) y la hipótesis alternativa \(H_{1}\). Se suele plantear formalmente \[ \left\{\begin{array}{ll} H_{0}:\text{hipótesis nula}\\ H_{1}:\text{hipótesis alternativa} \end{array} \right. \]
En los contrastes de hipótesis de este curso:
La hipótesis nula \(H_{0}\) es “no hay diferencia”, “no pasa nada”, “no hay nada extraño” o el equivalente en el contexto del contraste:
La moneda es equilibrada (50% de probabilidad de cara).
Los tratamientos A y B son igual de efectivos en la curación de la enfermedad X.
La hipótesis alternativa \(H_{1}\) plantea la diferencia de la que buscamos evidencia:
La moneda está trucada a favor de cara (más del 50% de probabilidad de cara).
A es más efectivo que B en la curación de la enfermedad X.
Estamos dispuestos a aceptar \(H_0\) por defecto: que no hay diferencia, que no pasa nada.
Por defecto, estamos dispuestos a aceptar que la moneda es equilibrada (la mayoría lo son, ¿no?).
Por defecto, estamos dispuestos a aceptar que los dos tratamientos son igual de efectivos (si tomáis dos sustancias cualesquiera y las administráis a enfermos de X, lo más normal es que ninguna de los dos tenga efecto alguno, y por lo tanto que las dos sean igual de (in)efectivas).
Si obtenemos evidencia suficiente de que \(H_0\) es falsa, rechazaremos \(H_0\) en favor de \(H_1\) y concluiremos que \(H_1\) es verdadera.
¿Qué quiere decir “obtener evidencia suficiente de que \(H_0\) es falsa”? Pues que las pruebas obtenidas hacen que \(H_0\) sea inverosímil (difícil de creer) por comparación con \(H_1\):
Tendremos evidencia de que la moneda está trucada a favor de cara si en nuestra serie de lanzamientos la proporción de caras es tan grande que se nos hace muy difícil creer que la moneda sea equilibrada.
Tendremos evidencia de que A es más efectivo que B en la curación de X si en nuestro ensayo la tasa de curación de la enfermedad X con el tratamiento A es tan superior a la de B que se nos hace muy difícil creer que los dos tratamientos tengan la misma efectividad.
Si no obtenemos evidencia suficiente de que \(H_0\) es falsa, es decir, si nuestros datos son razonablemente compatibles con \(H_0\), no podremos rechazarla. Entonces, aceptaremos la hipótesis nula.
Aceptaremos que la moneda no está trucada a favor de cara si en nuestra serie de lanzamientos la proporción de caras no es lo bastante grande como para hacernos dudar de que sea equilibrada
Aceptaremos que A es igual de efectivo que B en la curación de X si en nuestro ensayo la tasa de curación de la enfermedad X con el tratamiento A no es lo bastante superior a la de B como para hacernos dudar de que los dos tratamientos sean igual de efectivos.
Por ejemplo, si en una secuencia de 30 lanzamientos de una moneda obtenemos todas las veces cara, seguramente lo consideraremos evidencia de que la moneda está trucada, pero no demuestra que la moneda esté trucada. Sí, cuesta creer que no esté trucada, pero no es imposible: la moneda podría ser equilibrada y por puro azar nosotros haber tenido esta racha de caras. Y tampoco podemos decir que sea improbable que sea equilibrada, puesto que no sabemos calcular \[ P(\text{La moneda es equilibrada}\,|\,\text{30 caras en 30 lanzamientos}). \] Lo que sabemos calcular es \[ P(\text{30 caras en 30 lanzamientos}\,|\,\text{La moneda es equilibrada}) \] que vale \(0.5^{30}=9.3\cdot 10^{-10}\) (y por lo tanto, de media, aproximadamente en una de cada mil millones de veces que se efectúan 30 lanzamientos seguidos de una moneda equilibrada, se obtienen 30 caras: no es imposible).
Por ejemplo, si en una secuencia de 4 lanzamientos de una moneda obtenemos 2 caras, tendremos que aceptar que la moneda es equilibrada. Pero podría ser que estuviera ligeramente sesgada hacia cara y no haberse notado en una secuencia tan corta de lanzamientos. Así que no hemos encontrado evidencia de que sea equilibrada, simplemente no lo podemos descartar (como tampoco podemos descartar que la probabilidad de cara sea, por ejemplo, 0.50001).
Ejemplo 14.1 En un juicio (en el que el acusado es inocente si no se demuestra lo contrario) se busca evidencia suficiente de que el acusado es culpable. Por lo tanto, esta es la hipótesis alternativa. Por otro lado, que “no pase nada” significa que el acusado es inocente: casi todo el mundo es inocente del cargo concreto que se juzga en ese momento. Esta será la hipótesis nula. Por lo tanto, el contraste es:
\[ \left\{\begin{array}{ll} H_{0}:\text{El acusado es inocente}\\ H_{1}:\text{El acusado es culpable} \end{array} \right. \] En el juicio se aportan pruebas, y:
Si el jurado las encuentra lo bastante incriminatorias, “más allá de toda duda razonable”, declara culpable el acusado (rechaza \(H_0\) en favor de \(H_1\)).
Si el jurado no las encuentra lo bastante incriminatorias, lo considera no culpable (no rechaza \(H_{0}\)).
Observad que considerar no culpable no es lo mismo que demostrar que es inocente: simplemente, se considera que el acusado no es culpable porque no se ha encontrado evidencia suficiente de que sea culpable.
Ejemplo 14.2 Un examen es un contraste de hipótesis. En este caso, “no pasa nada” significa que el estudiante es como si no hubiera ido al curso, no ha aprendido nada, y por lo tanto esta es la hipótesis nula. Con el examen buscamos evidencia de que el estudiante ha aprendido la materia, por lo tanto esta será la hipótesis alternativa. Así pues, el contraste es:
\[ \left\{\begin{array}{ll} H_{0}:\text{El estudiante no sabe la materia}\\ H_{1}:\text{El estudiante sabe la materia} \end{array} \right. \] Tomamos una muestra de los conocimientos del estudiante (el estudiante hace el examen), y:
Si hay suficiente evidencia en favor de \(H_1\) (si el examen le sale lo bastante bien), rechazamos \(H_0\): decidimos que el estudiante sabe la materia, aprueba la asignatura.
Si no hay evidencia suficiente en favor de \(H_1\) (si el examen no le sale lo bastante bien), nos quedamos con \(H_0\): concluimos que el estudiante no ha aprendido la materia, suspende la asignatura.
Ejemplo 14.3 Una prueba diagnóstica de una enfermedad es un contraste de hipótesis. En este caso, “no pasa nada” significa que la persona no tiene la enfermedad, y por lo tanto esta es la hipótesis nula. Con la prueba diagnóstica buscamos evidencia de que tiene la enfermedad, por lo tanto esta será la hipótesis alternativa. Es decir, el contraste es
\[ \left\{\begin{array}{ll} H_{0}:\text{La persona no tiene la enfermedad}\\ H_{1}:\text{La persona sí tiene la enfermedad} \end{array} \right. \]
Ejemplo 14.4 Si leemos la noticia siguiente en el diario, puede que nos preguntemos si es verdad que las mujeres practican menos deporte que los hombres.

Esta pregunta la podemos plantear de muchas maneras:
¿Toda mujer hace cada día menos horas de deporte que cualquier hombre?
Si tomo una mujer y un hombre al azar, ¿es más probable que ella practique menos deporte que él?
¿La mayoría de las mujeres hacen cada día menos horas de deporte que la mayoría de los hombres?
¿La proporción de practicantes de deporte entre las mujeres es menor que entre los hombres?
¿La media semanal de veces que las mujeres practican deporte es menor que la de los hombres?
¿La media semanal de horas que las mujeres practican deporte es menor que la de los hombres?
…
Cada una de estas preguntas se traduciría en un contraste de hipótesis diferente. Puesto que aquí estamos tratando contrastes sobre parámetros poblacionales (medias, proporciones, etc.), podríamos plantear alguno de los tres últimos contrastes. Vamos a centrarnos en la última cuestión, sobre medias semanales de horas de deporte.
En este contraste, las variables poblacionales de interés son:
\(X_m\): “Tomo una mujer y calculo su número medio de horas semanales de deporte”, con media \(\mu_m\): la media semanal de horas de deporte de las mujeres (la media de las medias de horas semanales de deporte de todas las mujeres es la media de horas semanales de deporte de las mujeres).
\(X_h\): “Tomo un hombre y calculo su número medio de horas semanales de deporte”, con media \(\mu_h\): la media semanal de horas de deporte de los hombres.
El contraste que queremos realizar es
Hipótesis nula: no hay diferencia entre las medias semanales de horas de deporte de hombres y mujeres.
Hipótesis alternativa: la media semanal de horas de deporte de las mujeres es menor que la de los hombres.
Es decir \[ \left\{\begin{array}{ll} H_{0}: \mu_m=\mu_h\\ H_{1}:\mu_m<\mu_h \end{array} \right. \]
El procedimiento para llevar a cabo este contraste sería:
Tomaríamos muestras aleatorias de mujeres y de hombres y les preguntaríamos sus hábitos de práctica de deporte.
Calcularíamos la media muestral \(\overline{X}_m\) de horas semanales de deporte de las mujeres de la muestra.
Calcularíamos la media muestral \(\overline{X}_h\) de horas semanales de deporte de los hombres de la muestra.
Si \(\overline{X}_m\) fuera mucho menor que \(\overline{X}_h\), lo tomaríamos como evidencia de que \(\mu_m<\mu_h\).
Si \(\overline{X}_m\) no fuera mucho menor que \(\overline{X}_h\), no podríamos rechazar que \(\mu_m=\mu_h\).
¿Qué significa “\(\overline{X}_m\) mucho menor que \(\overline{X}_h\)”? Una opción, que podríamos importar del tema anterior, seria calcular un intervalo de confianza del 95% para \(\mu_m-\mu_h\) a partir de la muestra. Entonces:
Si este intervalo de confianza estuviera totalmente a la izquierda del 0, con un 95% de confianza podríamos concluir que \(\mu_m<\mu_h\) (porque tendríamos un 95% de seguridad de que el valor real de la diferencia \(\mu_m-\mu_h\) pertenece a un intervalo de números estrictamente negativos).
En caso contrario (si contuviera el 0 o si estuviera totalmente a la derecha del 0), con un 95% de confianza no podríamos concluir que \(\mu_m<\mu_h\).
Aquí querremos afinar un poco más que lo del “nivel de confianza”, por lo que el procedimiento será algo más complicado. Básicamente, la idea es que vamos a usar diferentes fórmulas para calcular los intervalos de confianza según la forma de la hipótesis alternativa, ya lo veremos.
Antes de cerrar esta sección, queremos destacar algunas advertencias.
En el ejemplo anterior, las hipótesis del contraste comparaban las medias poblacionales de horas semanales de deporte de las mujeres y los hombres, no las medias de horas semanales de deporte de las mujeres y los hombres de la muestra.
Para comparar las medias muestrales no nos hace falta un contraste de hipótesis: las calculamos y punto. En cambio, como no podemos calcular las medias semanales de horas de deporte de todas las mujeres y de todos los hombres, nos vemos obligados a hacer un contraste de hipótesis.
Si no podemos asegurar que las mujeres practiquen menos deporte que los hombres (porque no hayamos encontrado evidencia a favor de esta hipótesis), esto no significará que hayamos encontrado evidencia de que los hombres y las mujeres practiquen la misma cantidad de deporte o de que las mujeres practiquen más deporte. Lo que significará es que la evidencia en favor de \(H_1\) no ha sido lo bastante contundente como para poder concluir que esta es la hipótesis verdadera y por lo tanto aceptamos que no hay diferencia en la media semanal de horas de deporte de ambos sexos.
Si por ejemplo en nuestro estudio hubiéramos encontrado que \(\overline{X}_m=\overline{X}_h\), esto sería compatible con la hipótesis nula \(\mu_m=\mu_h\), y por eso no la podríamos rechazar. Pero no aportaría evidencia de que \(\mu_m=\mu_h\), puesto que seguramente también sería compatible, por ejemplo, con \(\mu_m=\mu_h+0.0007\) (las mujeres hacen, de media, un minuto más de deporte a la semana que los hombres) y por lo tanto, si “ser compatible” fuera lo mismo que “aportar evidencia”, nuestros datos aportarían evidencia de que dos hipótesis que se contradicen son verdaderas.
Tenemos que plantear la pregunta antes de recoger la muestra. Si estamos interesados en el contraste \[ \left\{\begin{array}{ll} H_{0}: \mu_m=\mu_h\\ H_{1}:\mu_m<\mu_h \end{array} \right. \] y obtenemos que \(\overline{X}_m\) es mucho mayor que \(\overline{X}_h\) en nuestra muestra, concluimos que no tenemos evidencia de que \(\mu_m<\mu_h\) y punto. Sería hacer trampas decir: “No hemos encontrado evidencia de que las mujeres practiquen menos deporte que los hombres, pero si con estos mismos datos realizamos el contraste \[ \left\{\begin{array}{ll} H_{0}: \mu_m=\mu_h\\ H_{1}:\mu_m>\mu_h \end{array} \right. \] sí que obtenemos evidencia de que ellas practican más deporte que ellos.”
De esto se dice ir a pescar evidencias o también torturar los datos: obtener unos datos y buscar de qué dan evidencia. Es mala praxis científica. Cualquier conjunto de datos, si lo torturamos lo suficiente, acaba dando evidencia de algo.
No confundáis \[ \left\{\begin{array}{ll} H_{0}: \mu_m=\mu_h\\ H_{1}:\mu_m<\mu_h \end{array} \right. \] con \[ \left\{\begin{array}{ll} H_{0}: \mu_m=\mu_h\\ H_{1}:\mu_m \neq \mu_h \end{array} \right. \] que traduce la pregunta “Los hombres y las mujeres, ¿practican deporte un número diferente de horas a la semana, de media?”
Reglas para elegir \(H_0\) y \(H_1\) en este curso:
\(H_0\) siempre se tiene que definir mediante una igualdad.
\(H_1\) es la hipótesis de la que buscamos evidencia, y se tiene que definir mediante algo “estricto”:
Hipótesis unilateral (one-sided; también de una cola, one-tailed): definida con < o con >.
Hipótesis bilateral (two-sided; también de dos colas, two-tailed): definida con \(\mathbf{\neq}\).
Los contrastes toman el nombre del tipo de hipótesis alternativa: contraste unilateral, contraste de dos colas, etc.
14.2 Un ejemplo
Tenemos una moneda, y creemos que está trucada en favor de cara. Queremos contrastarlo.
Aquí la variable aleatoria \(X\) que nos interesa es “lanzamos la moneda y miramos si sale cara”, que es de Bernoulli con probabilidad de éxito (es decir, probabilidad de sacar cara con nuestra moneda) \(p_{\mathit{Cara}}\).
La hipótesis nula será que la moneda no está trucada (no le pasa nada a nuestra moneda), y la alternativa que la moneda está trucada en favor de cara. En términos de \(p_{\mathit{Cara}}\), el contraste es \[ \left\{\begin{array}{ll} H_{0}:p_{\mathit{Cara}}= 0.5\\ H_{1}:p_{\mathit{Cara}}> 0.5 \end{array} \right. \]
Ejemplo 14.5 Supongamos que lanzamos la moneda 3 veces y obtenemos 3 caras. ¿Es evidencia suficiente de que está trucada a favor de cara?
Llamemos \(S_3\) a la variable aleatoria “Número de caras en 3 lanzamientos de esta moneda.” Si la moneda no está trucada, \(S_3\) es binomial \(B(3,0.5)\), y por lo tanto \[ P(S_3=3)=0.5^{3}=0.125. \]
El resultado obtenido no es muy improbable con una moneda equilibrada: pasa, de media, en 1 de cada 8 secuencias de 3 lanzamientos. Por lo tanto, no vamos a considerarlo evidencia suficiente de que la moneda esté trucada. Aceptamos que la moneda es equilibrada.
Ejemplo 14.6 Supongamos que ahora lanzamos la moneda 10 veces y obtenemos 10 caras. ¿Es evidencia suficiente de que está trucada a favor de cara?
Llamemos \(S_{10}\) a la variable aleatoria “Número de caras en 10 lanzamientos.” Si la moneda no está trucada, \(S_{10}\) es \(B(10,0.5)\) y por lo tanto \[ P(S_{10}=10)=0.5^{10}=0.001 \]
El resultado obtenido es bastante improbable si la moneda no está trucada: si la moneda fuera equilibrada, de media solo en 1 de cada 1000 secuencias de 10 lanzamientos obtendríamos 10 caras. Es decir:
El resultado de nuestro experimento sería muy raro si la moneda fuera equilibrada, lo que nos hace dudar de que sea equilibrada.
Lo consideramos evidencia de que está trucada.
Observad el razonamiento que hemos efectuado. Tenemos una hipótesis nula y una alternativa, realizamos un experimento y obtenemos un resultado que es muy improbable si la hipótesis nula es verdadera. Una de dos:
- O la hipótesis nula es falsa.
- O la hipótesis nula es verdadera y ha pasado algo muy raro.
El procedimiento que hemos seguido en los dos ejemplos anteriores ha sido el siguiente:
Hemos planteado el contraste: \[ \left\{\begin{array}{ll} H_{0}:p_{\mathit{Cara}}= 0.5\\ H_{1}:p_{\mathit{Cara}}> 0.5 \end{array} \right. \]
Hemos recogido una muestra aleatoria simple de valores: la secuencia de lanzamientos.
Hemos elegido un estadístico de contraste con distribución de probabilidades conocida cuando \(H_0\) es verdadera: en nuestro caso, el número de caras.
Hemos calculado el valor de este estadístico sobre nuestra muestra.
Hemos calculado la probabilidad de que el estadístico tome el valor observado si \(H_0\) es verdadera.
Si esta probabilidad es muy pequeña, lo tomamos como evidencia de que \(H_1\) es verdadera.
Si no es lo bastante pequeña, no consideramos que hayamos obtenido evidencia de que \(H_0\) sea falsa y \(H_1\) verdadera.
Bien, esto es lo que hemos hecho, pero no es del todo correcto. En los puntos (5) y (6) decimos que: “Calculamos la probabilidad de que el estadístico tome el valor observado si \(H_0\) es verdadera y si es muy pequeña, lo consideramos evidencia de que \(H_1\) es verdadera.” ¿Seguro que queremos hacer esto?
Supongamos que, en el contraste anterior, lanzamos la moneda 10 veces y obtenemos 10 cruces. ¿Es evidencia suficiente de que está trucada en favor de cara? Obviamente no lo puede ser, pero la probabilidad es la misma que antes: \[ P(S_{10}=0)=0.5^{10}=0.001 \]
En muchos casos, la probabilidad de obtener exactamente lo que hemos obtenido puede ser muy pequeña, independientemente de lo que hayamos obtenido. Por ejemplo, supongamos que lanzamos la moneda 10000 veces y obtenemos 5000 caras. Si la moneda es equilibrada, el número de caras seguirá una distribución binomial \(B(10000,0.5)\) y la probabilidad de obtener 5000 caras será \[ \binom{10000}{5000}0.5^{10000}=0.008 \] muy pequeña, pero está claro que si la mitad de lanzamientos dan cara, no se puede considerar evidencia de que la moneda esté trucada.
O, más exagerado aún, si el estadístico de contraste es una variable continua, la probabilidad de que tome un valor concreto, el que sea, es 0 por definición. Más pequeño imposible, pero no siempre rechazaremos la hipótesis nula.

Figura 14.1: “Null hypothesis” (https://xkcd.com/892/ (CC-BI-NC 2.5))
Así que:
En nuestro ejemplo de la moneda, como la hipótesis nula es \(p_{\mathit{Cara}}= 0.5\) y la hipótesis alternativa es \(p_{\mathit{Cara}}> 0.5\), el p-valor es la probabilidad de que, si \(p_{\mathit{Cara}}= 0.5\), el número de caras sea mayor o igual que el obtenido en nuestra muestra.
En los dos ejemplos anteriores concretos, donde obteníamos 3 caras en 3 lanzamientos y 10 caras en 10 lanzamientos, era lo mismo pedir que el número de caras fuera igual al obtenido y pedir que el número de caras fuera mayor o igual que el obtenido, porque en los dos experimentos hemos obtenido el número máximo posible de caras; por ejemplo, sacar 3 o más caras en 3 lanzamientos es exactamente lo mismo que sacar 3 caras en 3 lanzamientos. Pero en general esto no será así.
Ejemplo 14.7 Volvamos a nuestro contraste \[ \left\{\begin{array}{ll} H_{0}:p_{\mathit{Cara}}= 0.5\\ H_{1}:p_{\mathit{Cara}}> 0.5 \end{array} \right. \] Supongamos que lanzamos la moneda 10 veces y obtenemos 7 caras. ¿Es evidencia suficiente de que está trucada a favor de cara?
Seguimos llamando \(S_{10}\) a la variable aleatoria “Número de caras en 10 lanzamientos”. Si la moneda no está trucada, \(S_{10}\) es \(B(10,0.5)\). Como la hipótesis alternativa es \(p_{\mathit{Cara}}> 0.5\), “obtener un número de caras tan extremo o más que el que hemos obtenido en el sentido de la hipótesis alternativa” es sacar tantas caras como las que hemos obtenido o más, es decir sacar 7 o más caras. Por lo tanto \[ \text{p-valor}=P(S_{10}\geqslant 7)=0.172 \]
Un número de caras igual o superior al obtenido no es muy improbable si la moneda no está trucada: pasaría en 1 de cada 6 secuencias de 10 lanzamientos. Por lo tanto, como es bastante compatible con el equilibrio de la moneda, no lo podemos considerar evidencia de que esté trucada a favor de cara.
Ejemplo 14.8 Tenemos una moneda, y ahora creemos que está trucada a favor de cruz. Queremos contrastarlo. Planteado en términos de \(p_{\mathit{Cara}}\), el contraste que queremos realizar es \[ \left\{\begin{array}{ll} H_{0}:p_{\mathit{Cara}}= 0.5\\ H_{1}: p_{\mathit{Cara}}< 0.5 \end{array} \right. \] Imaginad que lanzamos la moneda 10 veces y obtenemos 1 cara. ¿Es suficiente evidencia de que \(p_{\mathit{Cara}}< 0.5\)?
Seguimos llamando \(S_{10}\) a la variable aleatoria “Número de caras en 10 lanzamientos de esta moneda.” Si la moneda no está trucada, \(S_{10}\) es \(B(10,0.5)\).
Ahora, como \(H_{1}\) es \(p_{\mathit{Cara}}< 0.5\), “obtener un número de caras tan extremo o más que el que hemos obtenido, en el sentido de la hipótesis alternativa” es sacar tantas caras como las que hemos obtenido o menos, es decir sacar como máximo 1 cara. Por lo tanto \[ \text{p-valor}=P(S_{10}\leqslant 1)=0.01 \] Un resultado tan o más extremo como el obtenido es muy improbable si \(p_{\mathit{Cara}}= 0.5\): de media, solo ocurre en 1 de cada 100 secuencias de 10 lanzamientos. Lo podemos considerar evidencia de que la moneda sí que está trucada en favor de cruz.
14.3 El p-valor
El p-valor de un contraste es la probabilidad de que, si la hipótesis nula es verdadera, el estadístico de contraste tome en una muestra aleatoria simple del mismo tamaño que la nuestra un valor tan o más extremo, en el sentido de la hipótesis alternativa, que el obtenido con la muestra usada para realizar el contraste.
Lo repetimos, poniendo énfasis en los componentes fundamentales de la definición. El p-valor es:
- La probabilidad de que,
- si la hipótesis nula es verdadera,
- el estadístico de contraste tome en una muestra aleatoria simple del mismo tamaño que la nuestra
- un valor tan o más extremo, en el sentido de la hipótesis alternativa,
- que el obtenido con nuestra muestra.
Ejemplo 14.9 Supongamos que en el contraste de las medias semanales de horas de deporte de hombres y mujeres del Ejemplo 14.4 usamos como estadístico de contraste la diferencia entre las medias muestrales \(\overline{X}_m-\overline{X}_h\) (no será así: ¡solo es un ejemplo!), que hemos tomado muestras de 50 mujeres y de 50 hombres, y que la diferencia de medias muestrales ha sido -1.2. Entonces, el p-valor del contraste es
La probabilidad de que,
si la hipótesis nula es verdadera,
si \(\mu_m=\mu_h\), es decir, si los hombres y las mujeres practican de media el mismo número de horas de deporte a la semana,
el estadístico de contraste tome en una muestra aleatoria simple del mismo tamaño que la nuestra
el valor de \(\overline{X}_m-\overline{X}_h\), es decir, de la diferencia entre las medias muestrales de horas semanales de deporte en las mujeres y en los hombres, en una muestra aleatoria formada por 50 mujeres y 50 hombres, sea
un valor tan o más extremo, en el sentido de la hipótesis alternativa,
menor o igual (porque la hipótesis alternativa es \(\mu_m<\mu_h\), es decir \(\mu_m-\mu_h<0\))
que el obtenido con nuestra muestra.
que el de nuestra muestra, -1.2.
En resumen, el p-valor seria en este caso
La probabilidad de que, si \(\mu_m=\mu_h\), el valor de \(\overline{X}_m-\overline{X}_h\) en una muestra aleatoria de 50 mujeres y 50 hombres sea menor o igual que -1.2.
Si esta probabilidad es muy pequeña, la muestra obtenida es poco consistente con la hipótesis nula y por lo tanto concluiremos que la hipótesis alternativa es verdadera. Si, en cambio, esta probabilidad no es muy pequeña, la muestra obtenida es consistente con la hipótesis nula y por lo tanto no podremos rechazar que \(H_0\) sea verdadera.
El p-valor NO es:
La probabilidad de que \(H_0\) sea verdadera condicionada a nuestro resultado.
La probabilidad de que \(H_1\) sea falsa condicionada a nuestro resultado.
Es al revés: El p-valor es la probabilidad de nuestro resultado (o uno más extremo) condicionada a que \(H_0\) sea verdadera. Por lo tanto, el p-valor es una evidencia indirecta inversa de \(H_1\):
Cuanto menor sea el p-valor, más raro sería lo que hemos obtenido si \(H_0\) fuera verdadera y \(H_1\) falsa, y por lo tanto más evidencia aporta de que \(H_0\) no puede ser verdadera y de que la verdadera es \(H_1\).
Por ejemplo, si el p-valor de un contraste es 0.03:
Significa que, si \(H_0\) fuera verdadera, el estadístico de contraste valdría en 3 de cada 100 muestras algo al menos tan extremo, en el sentido de \(H_1\), como lo que hemos obtenido.
¿Lo encontráis poco? Lo tomáis como evidencia de que \(H_0\) es falsa y \(H_1\) verdadera.
¿No lo encontráis poco? No tenéis evidencia para rechazar que \(H_0\) sea verdadera.
Pero no significa que:
La probabilidad de que \(H_0\) sea verdadera es 0.03.
\(H_0\) es verdadera un 3% de las veces.
Ejemplo 14.10 Tenemos una moneda y nos preguntamos si está trucada; a favor de cara o a favor de cruz, nos da igual, solo si está trucada o es equilibrada.
Planteado en términos de la probabilidad de sacar cara \(p_{\mathit{Cara}}\), el contraste que queremos realizar ahora es \[ \left\{\begin{array}{ll} H_{0}:p_{\mathit{Cara}}= 0.5\\ H_{1}:p_{\mathit{Cara}}\neq 0.5 \end{array} \right. \] Supongamos que la lanzamos 10 veces y obtenemos 9 caras. ¿Es evidencia suficiente de que está trucada?
Como en la sección anterior, sea \(S_{10}\) la variable “Número de caras en 10 lanzamientos”. Si \(p_{\mathit{Cara}}= 0.5\), \(S_{10}\) es \(B(10,0.5)\).
Si la hipótesis nula fuera verdadera, esperaríamos sacar 5 caras y 5 cruces. Como la hipótesis alternativa es \(H_{1}:p_{\mathit{Cara}}\neq 0.5\), ahora “obtener un resultado tan o más extremo, en el sentido de la hipótesis alternativa, que el obtenido” es sacar un resultado que se aleje tanto, o más, de 5 caras y 5 cruces como el que hemos obtenido. Es decir, sacar al menos 9 caras o al menos 9 cruces, o lo que es el mismo, sacar o bien 9 o más caras, o bien 1 o menos caras. Por lo tanto, el p-valor es \[ \begin{array}{l} P(S_{10}\geqslant 9\text{ o }S_{10}\leqslant 1) =P(S_{10}\geqslant 9) + P(S_{10}\leqslant 1)\\ \qquad = 0.0107+0.0107=0.0214 \end{array} \]
Por lo tanto, si la moneda no estuviera trucada, un resultado tan alejado de “mitad caras, mitad cruces” como el nuestro se obtendría en alrededor de 1 de cada 50 secuencias de 10 lanzamientos. ¿Es evidencia suficiente de que esté trucada?
La respuesta corta es que seguramente sí. La respuesta larga es que depende de cuánto estemos dispuestos a arriesgarnos a rechazar la hipótesis nula cuando es verdadera.
14.4 Tipo de errores
La comparación entre la realidad y la conclusión de un contraste da lugar a cuatro situaciones posibles, resumidas en la tabla siguiente:

Si \(H_0\) es la hipótesis verdadera en la realidad y nosotros decidimos que \(H_1\) es verdadera:
La conclusión del contraste es errónea. Lo llamaremos un error de tipo I, error \(\alpha\) o falso positivo.
Denotaremos por \(\alpha\) la probabilidad de cometer un error de tipo I, es decir, de rechazar \(H_0\) si es verdadera, y la llamaremos el nivel de significación: \[ \alpha=P(\text{Rechazar } H_0\,|\, H_0\text{ verdadera}). \]
Si \(H_1\) es la hipótesis verdadera en la realidad y nosotros aceptamos \(H_0\):
La conclusión del contraste es errónea. Lo llamaremos un error de tipo II, error \(\beta\) o falso negativo.
Denotaremos por \(\beta\) la probabilidad de cometer un error de tipo II, es decir, de aceptar \(H_0\) si \(H_1\) es verdadera: \[ \beta=P(\text{Aceptar } H_0\,|\, H_1\text{ verdadera}). \]
Si \(H_1\) es la hipótesis verdadera en la realidad y nosotros decidimos rechazar \(H_0\) en favor de \(H_1\):
La conclusión del contraste es correcta. Lo llamaremos un verdadero positivo.
La probabilidad de acertar con un verdadero positivo es \(1-\beta\) y la llamaremos la potencia:
\[ 1-\beta=P(\text{Rechazar } H_0\,|\, H_1\text{ verdadera}). \]
Si \(H_0\) es la hipótesis verdadera en la realidad y nosotros la aceptamos:
La conclusión del contraste es correcta. Lo llamaremos un verdadero negativo.
La probabilidad de acertar con un verdadero negativo es \(1-\alpha\) y la llamaremos el nivel de confianza: \[ 1-\alpha=P(\text{Aceptar } H_0\,|\, H_0\text{ verdadera}). \]
En el contexto de un contraste de hipótesis,
Un resultado positivo es rechazar la hipótesis nula y decidir que la alternativa es la verdadera (hemos encontrado algo).
Un resultado negativo es aceptar la hipótesis nula (no hemos encontrado nada y nos quedamos con la hipótesis nula).
Repetimos:
El nivel de significación de un contraste es la probabilidad de que, si la hipótesis nula es verdadera, nosotros nos equivoquemos y la rechacemos en favor de la alternativa: \[ \alpha=P(\text{Rechazar } H_0\,|\, H_0\text{ verdadera}). \]
La potencia de un contraste es la probabilidad de que, si la hipótesis alternativa es verdadera, nosotros lo detectemos y rechacemos la hipótesis nula en favor de la alternativa: \[ 1-\beta=P(\text{Rechazar } H_0\,|\, H_1\text{ verdadera}). \]
Ejemplo 14.11 En un test de embarazo, el contraste que se realiza es: \[ \left\{\begin{array}{ll} H_{0}:\text{No estás embarazada}\\ H_{1}:\text{Estás embarazada} \end{array} \right. \]

Ejemplo 14.12 En un juicio, donde se tiene que declarar un acusado inocente o culpable, el contraste era \[ \left\{\begin{array}{ll} H_{0}:\text{El acusado es inocente}\\ H_{1}:\text{El acusado es culpable} \end{array} \right. \]
Se pueden cometer dos errores:
Error de tipo I: Declarar culpable a un inocente.
Error de tipo II: Declarar inocente a un culpable.
Es peor el error de tipo I, conviene minimizar la probabilidad de cometerlo. Por eso solo se declara a alguien culpable cuando las pruebas “lo demuestran más allá de toda duda razonable”.
Ejemplo 14.13 En un examen, el contraste era \[ \left\{\begin{array}{ll} H_{0}:\text{El estudiante no sabe la materia}\\ H_{1}:\text{El estudiante sabe la materia} \end{array} \right. \]
Los errores que pueden darse son:
Que apruebe un estudiante que no sabe la materia
Que suspenda un estudiante que sí sabe la materia
Normalmente, se considera peor cometer un error de tipo I que cometer un error de tipo II. Por lo tanto, el objetivo primario en un contraste es encontrar una regla de decisión que tenga poca probabilidad \(\alpha\) de error de tipo I. Pero también querríamos minimizar la probabilidad \(\beta\) de error de tipo II. El problema es que cuando hacemos que \(\alpha\) disminuya, \(\beta\) suele aumentar, porque al hacer más difícil rechazar la hipótesis nula, aumenta el riesgo de no rechazarla aunque sea falsa.
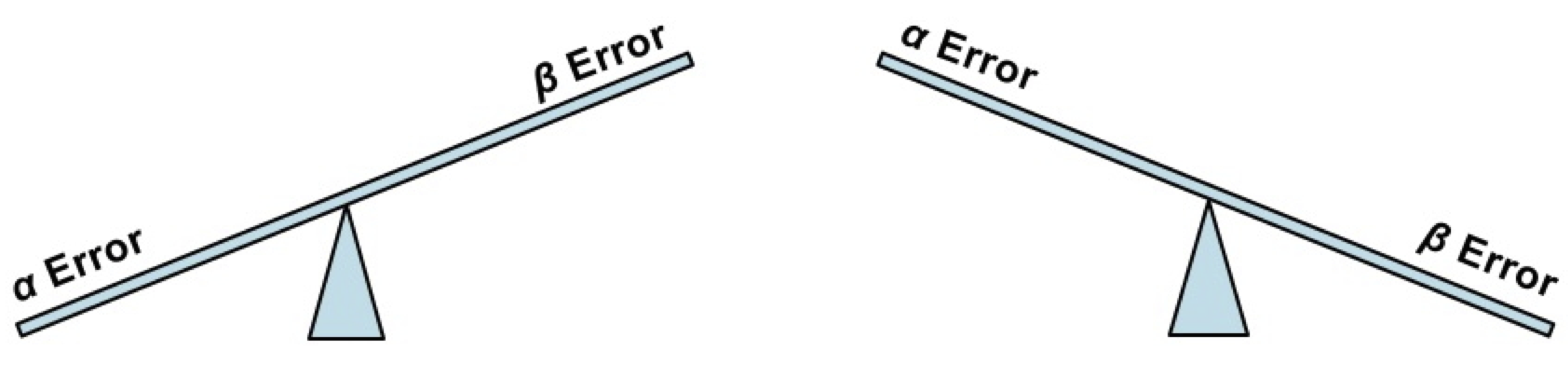
¿Qué se suele hacer?
Se da una regla de decisión para el nivel de significación \(\alpha\) deseado.
Después, se toma el tamaño \(n\) adecuado de la muestra para que la potencia sea la deseada.

Figura 14.2: No adoraréis falsos dioses.
Tomando este \(\alpha=0.05\), aceptamos una probabilidad de equivocarnos rechazando \(H_0\) en favor de \(H_1\) de 0.05. Es decir, asumimos que, de media, nos vamos a equivocar en 1 de cada 20 veces en que la hipótesis nula sea verdadera.
14.5 Ejemplo: El test t
La concentración media de calcio en plasma en hombres sanos de 22 a 44 años es de 2.5 mmol/l. Nos preguntamos si los hombres jóvenes con diabetes tienen una concentración de calcio en plasma mayor que estos 2.5 mmol/l. Traducimos esta cuestión en un contraste de hipótesis sobre la concentración media de calcio en plasma en los hombres jóvenes con diabetes, a la que llamaremos \(\mu\):
La hipótesis nula será que no hay diferencia entre \(\mu\) y la concentración media de calcio en plasma en los hombres jóvenes sanos, es decir, que \(\mu=2.5\)
La hipótesis alternativa es de lo que buscamos evidencia: que \(\mu>2.5\).
Por lo tanto, el contraste que queremos realizar es \[ \left\{\begin{array}{l} H_{0}:\mu=2.5\\ H_{1}:\mu >2.5 \end{array} \right. \]
Llamemos \(X\) a la variable aleatoria “Tomamos un hombre diabético de 22 a 44 años y le medimos la concentración de calcio en plasma en mmol/l”, cuya media hemos llamado \(\mu\). Vamos a suponer en esta sección que esta variable \(X\) sigue una ley normal.
En una muestra de 40 diabéticos de esta franja de edad, se obtuvo una concentración media de calcio en plasma de \(\overline{x}=3.2\) mmol/l con una desviación típica muestral \(\widetilde{s}=1.5\). Vamos a suponer que podemos considerar esta muestra de diabéticos jóvenes como aleatoria simple.
Nos encontramos ante un caso particular de la situación siguiente. Tenemos una variable aleatoria poblacional \(X\) normal de media \(\mu\) y planteamos el contraste \[ \left\{\begin{array}{l} H_{0}:\mu=\mu_0\\ H_{1}:\mu >\mu_0 \end{array} \right. \] para un valor concreto \(\mu_0\). Queremos tomar una decisión a partir de una muestra aleatoria simple.
La idea es que rechazaremos \(H_0\) en favor de \(H_1\) si la media muestral es mucho mayor que \(\mu_0\): tanto, que sería muy improbable que fuera así de grande si la media poblacional fuera exactamente \(\mu_0\). El problema es que no sabemos calcular \(P(\overline{X}-\mu_0)\) si solo sabemos que \(X\) es normal de media \(\mu_0\), porque no sabemos la distribución de \(\overline{X}\) (sabemos que será normal de media \(\mu_0\), pero desconocemos su desviación típica). Por lo tanto tenemos que usar otro estadístico de contraste, \(\overline{X}\) no funcionará.
Llegados a este punto, nos acordamos de que si \(H_0\) es verdadera, es decir, si la media de \(X\) es \(\mu_0\), entonces \[ T=\frac{\overline{X}-\mu_0}{{\widetilde{S}_X}/{\sqrt{n}}} \] tiene distribución \(t_{n-1}\). Y podemos traducir que “\(\overline{X}\) sea mucho mayor que \(\mu_0\)” en que “\(T\) sea mucho mayor que 0”.
Entonces, la idea que guiará el procedimiento para tomar una decisión en este contraste será la siguiente:
Rechazaremos \(H_0\) en favor de \(H_1\) si este estadístico de contraste \(T\) toma un valor “muy grande” sobre la muestra.
La definición precisa de “muy grande” dependerá del valor de \(\alpha\) que queramos tomar, es decir, de la probabilidad de cometer un error de tipo I que estemos dispuestos a asumir: cuanto menor queramos que sea \(\alpha\), mayor tendrá que ser la evidencia a favor de \(\mu>\mu_0\), es decir, mayor tendrá que ser \(T\). Aquí vamos a tomar el valor usual \(\alpha=0.05\).
Sea \(T_0\) el valor que toma el estadístico de contraste \(T\) en nuestra muestra. Rechazaremos \(H_{0}\) si \(T_0\) es mayor que un cierto umbral \(L_0\), que determinamos a partir de \(\alpha\):
\[ \begin{array}{l} \alpha = P(\text{Rechazar } H_{0}\,|\, H_{0} \text{ cierta})=P(T> L_0)\\ \qquad\quad \Longrightarrow 1-\alpha= P(T\leqslant L_0)\Longrightarrow L_0= t_{n-1,1-\alpha} \end{array} \]
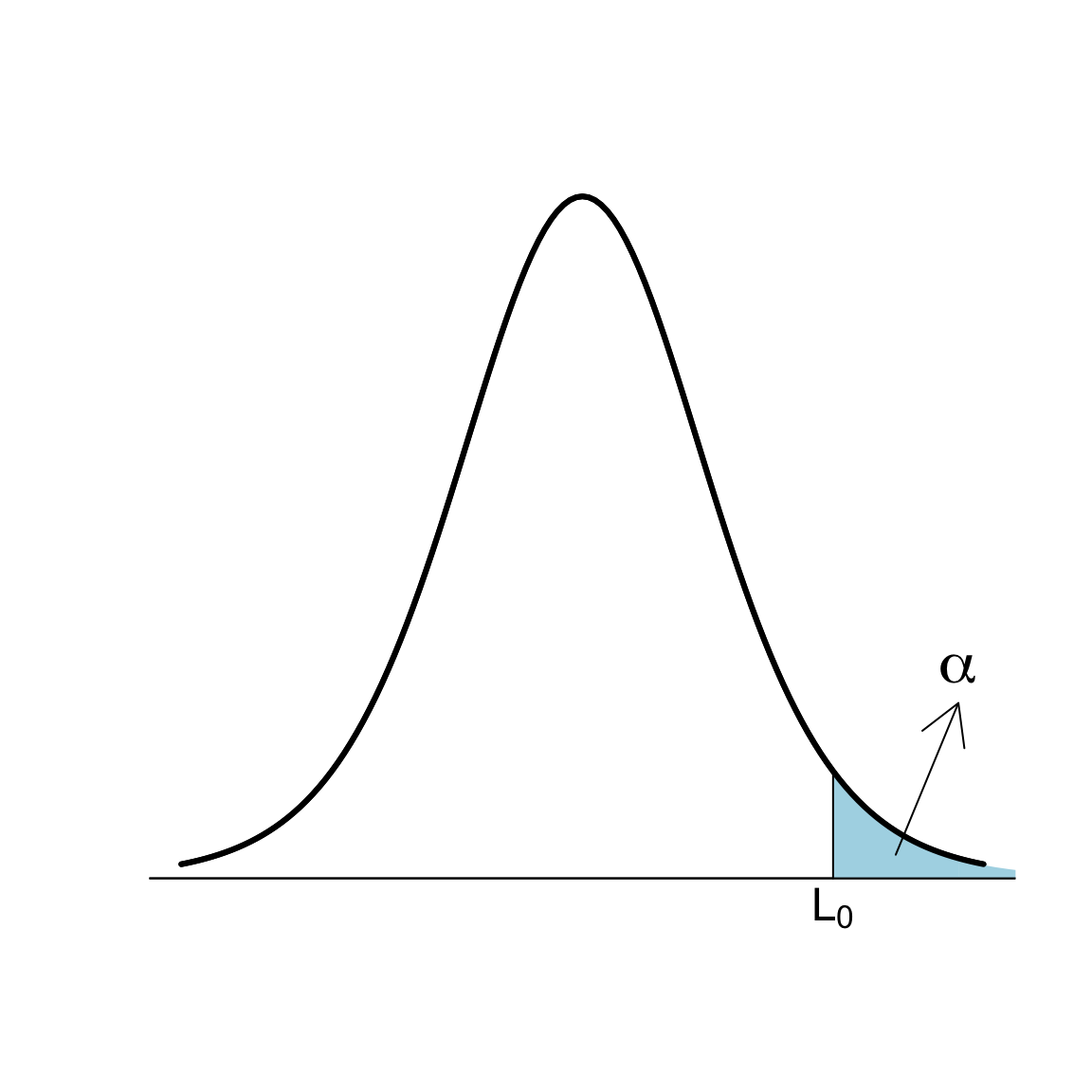
Por lo tanto, para que el nivel de significación del contraste sea \(\alpha\),
Rechazaremos \(H_0\) si \(T_0>t_{n-1,1-\alpha}\)
Llamaremos a esta regla una regla de rechazo para este tipo de contraste.
Volvamos a nuestro ejemplo de los jóvenes diabéticos \[ \left\{\begin{array}{l} H_{0}:\mu=2.5\\ H_{1}:\mu > 2.5 \end{array} \right. \] Si \(\alpha=0.05\) y \(n=40\), el umbral a partir del cual rechazamos \(H_0\) es \(t_{n-1,1-\alpha}=t_{39,0.95}=1.685\).
En nuestra muestra tenemos que \(\overline{x}=3.2\), \(\widetilde{s}=1.5\) y \(n=40\), por lo tanto el estadístico de contraste vale \[ T_0=\frac{3.2-2.5}{1.5/\sqrt{40}}=2.95 \]
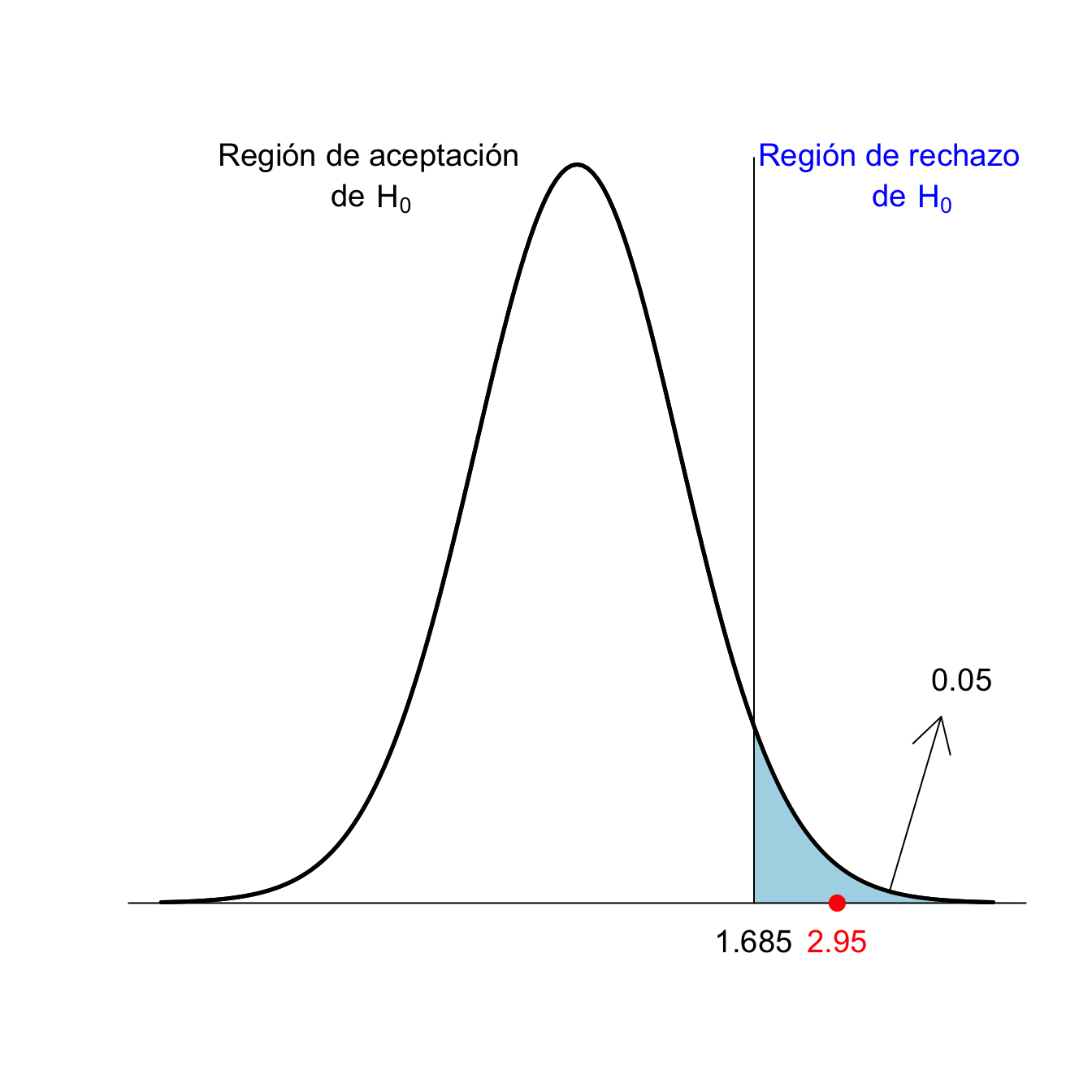
Como 2.95>1.685, concluimos con un nivel de significación del 5% que el nivel medio de calcio en sangre en los jóvenes diabéticos es mayor que en los jóvenes sanos.
Vamos a ver cómo entra en juego el p-valor. Recordad que rechazamos \(H_0\) cuando \(T_0>t_{n-1,1-\alpha}\): \[ \begin{array}{l} \text{Rechazamos $H_0$} \Longleftrightarrow T_0> t_{n-1,1-\alpha}\\ \qquad \Longleftrightarrow P(T\geqslant T_0)< P(T\geqslant t_{n-1,1-\alpha})\\ \qquad \Longleftrightarrow P(T\geqslant T_0)< 1-P(T\leqslant t_{n-1,1-\alpha})=1-(1-\alpha)=\alpha\\ \qquad \Longleftrightarrow P(T\geqslant T_0)<\alpha \end{array} \]
I ahora notad que \(P(T\geqslant T_0)\) es la probabilidad de que, si \(H_0\) es verdadera, el estadístico de contraste \(T\) tome un valor tan o más extremo, en el sentido de \(H_1: \mu>2.5\), que el obtenido en nuestra muestra, \(T_0\): ¡es el p-valor del contraste! Por lo tanto, tenemos otra regla de rechazo, equivalente a la anterior:
Rechazaremos \(H_0\) si el p-valor es menor que \(\alpha\)
En nuestro ejemplo, ya hemos calculado \(T_0=2.95\). Entonces, \[ \text{p-valor} =P(T\geqslant 2.95)=P(t_{39}\geqslant 2.95)=0.003 \] Como el p-valor es menor que 0.05:
Concluimos con un nivel de significación del 5% que el nivel medio de calcio en plasma de los jóvenes diabéticos es mayor que el de los jóvenes sanos.
Esto se suele expresar diciendo que
Hemos obtenido evidencia estadísticamente significativa de que el nivel medio de calcio en plasma de los jóvenes diabéticos es mayor que el de los jóvenes sanos.
\[ T=\frac{\overline{X}-\mu_0}{{\widetilde{S}_X}/{\sqrt{n}}} \] sigue una distribución t de Student con \(n-1\) grados de libertad, \(t_{n-1}\), se le llama un test t. En la próxima lección explicaremos cuándo se puede usar.
Fijaos en que nuestra conclusión ha sido que “concluimos con un nivel de significación del 5% que el nivel medio de calcio en sangre de los jóvenes diabéticos es mayor que el de los jóvenes sanos.” Por lo tanto, aceptamos una probabilidad del 5% de cometer un falso positivo. Si en realidad el nivel medio de calcio en sangre de los jóvenes diabéticos fuera el mismo que el de los sanos, la probabilidad que tendríamos de equivocarnos y concluir que el nivel medio de calcio en sangre de los jóvenes diabéticos es mayor que el de los sanos es del 5%.
Ejemplo 14.14 Vamos a estudiar esta tasa de aciertos por medio de una simulación.
Primero supondremos que el nivel medio real es 2.5, y simularemos la probabilidad de error de tipo I. Como estamos realizando el contraste con nivel de significación 0.05, esperamos alrededor de un 5% de errores de tipo I. Para fijar ideas, modelaremos la población de jóvenes diabéticos por medio de una variable aleatoria normal \(N(2.5,0.5)\). La \(\sigma=0.5\) nos la hemos inventado. Damos el código R de la simulación, por si la queréis repetir en casa. Cada simulación dará resultados diferentes, pero en general serán muy parecidos a los nuestros.
El umbral \(L_0\) para \(n=40\) y \(\alpha=0.05\) es \(t_{39,0.975}\):
## [1] 1.684875La función estadístico siguiente toma una muestra aleatoria de tamaño \(n\) de una variable \(N(\mu, \sigma)\) y calcula el estadístico de contraste \(T\):
estadístico=function(n,mu,sigma){
muestra=rnorm(n,mu,sigma)
(mean(muestra)-mu0)/(sd(muestra)/sqrt(n))
}Ahora, repetimos 200 veces el proceso de tomar una muestra aleatoria de tamaño 40 de nuestra población y calcular la \(T\) correspondiente. Llamamos Tes al vector de estos valores de \(T\):
## [1] -0.204556115 0.551277014 0.317804933 -1.916424317 0.228799593
## [6] -0.636252541 0.546424036 -0.411971051 -0.424224911 1.184281984
## [11] -1.372747727 0.319514212 -0.485567240 0.724620331 -1.114121167
## [16] 1.002994827 -0.892700484 -2.394044325 -1.024911510 -1.273715103
## [21] -0.676221781 0.012311445 1.558797931 -0.189208386 1.137960594
## [26] -0.362377491 -1.342997649 0.100980325 0.532357160 -0.370579439
## [31] 0.577851111 -0.047777832 0.684704147 -1.208505741 -1.329676807
## [36] -0.284045263 -0.284095079 -0.291495898 -0.878941168 1.051862629
## [41] 1.579509611 1.251686082 2.045852094 -2.360865854 -0.103192516
## [46] 0.390701261 1.880219725 -0.018662794 -3.024762654 0.123696814
## [51] 0.761344572 -0.090605574 -2.687031800 0.801886366 -0.536807420
## [56] -0.028474151 0.196027879 0.682146866 1.411321489 -0.188707738
## [61] 1.546524165 -0.347908999 -0.026022121 0.209821139 0.805317582
## [66] 1.314081240 -0.839884569 0.396920453 0.660980262 -0.906549698
## [71] -0.359463173 -0.147452173 -0.064257189 -2.155846414 -0.139568976
## [76] -0.376455346 2.092808159 -0.709729535 -1.463534383 -1.809695988
## [81] 0.742383769 -0.622674376 0.983232702 0.788220841 -0.154184656
## [86] -1.161571197 -0.004649001 -0.438892198 -0.423543531 -0.264518977
## [91] 0.767939038 -0.182387180 0.080963916 0.320526506 0.280413272
## [96] 0.513633868 -1.638150471 -0.296678393 -0.543844147 0.392508189
## [101] -1.998219688 -1.462626783 -1.047438984 -1.051544062 0.875209713
## [106] -2.259121522 -0.001964387 -0.373639492 0.666057937 0.789694009
## [111] -0.702070906 3.201760850 0.722601940 0.197681171 -0.628662655
## [116] 2.445684957 -1.564835664 -0.421947252 -0.115222019 -0.670212416
## [121] 1.074994408 -1.144731548 0.014513287 -0.045690803 1.767038039
## [126] -0.490172630 -0.515288612 -0.723240119 0.114766130 2.233403900
## [131] 1.044936465 -0.924690832 1.853218655 -1.907551408 0.126266762
## [136] -0.688907166 1.117818143 1.821936572 0.329612552 0.071381075
## [141] -0.021639874 0.676769124 0.520849057 -2.006704343 -0.914341584
## [146] 0.585164132 0.655106533 0.119263816 0.262166125 0.803028099
## [151] -0.980923973 0.771922952 1.409751739 -0.831274271 0.946192097
## [156] -0.069357657 -2.266986664 1.339021435 -0.749638232 0.908952239
## [161] 0.413367570 2.009701264 0.455159446 -1.104914158 -0.643085983
## [166] -0.429874411 -0.196858070 -1.429470266 -2.181882962 1.466635278
## [171] 0.742815143 1.213190128 1.085521457 -1.497524599 -0.672070568
## [176] 0.262390233 0.852553576 0.390132290 1.692839873 -1.970368198
## [181] -1.173300556 -0.076807106 0.969328371 -0.284565211 -2.289453979
## [186] 0.535255778 -2.899705754 0.156836454 1.670103115 0.568690995
## [191] -2.543506854 -0.577244792 -1.696047276 0.991672787 -0.582753120
## [196] -2.219149723 0.109210103 0.279098618 -0.847558940 -1.390283286Finalmente, calculamos la proporción de veces que la \(T\) ha dado un valor mayor que el umbral \(L_0\), es decir, la proporción de veces que rechazamos la hipótesis nula \(\mu=2.5\) y que por lo tanto cometemos un error de tipo I.
## [1] 0.055Hemos cometido un 5.5% de errores de tipo I, muy cercano al 5% “poblacional” (en el conjunto de todas las muestras aleatorias que pudiéramos tomar).
Ahora vamos a suponer que el nivel medio real es estrictamente mayor que 2.5, y vamos a simular los errores de tipo II, para ver con qué frecuencia los cometemos. Para empezar, generamos al azar un vector de 100 \(\mu\)’s entre 2.6 y 3, de manera que todos los valores tengan la misma probabilidad de salir.
Para cada \(\mu_i\) de este vector, tomaremos como “población de diabéticos” una variable \(N(\mu_i,0.5)\). A continuación, para cada una de estas poblaciones, repetiremos 200 veces el proceso de tomar una muestra aleatoria simple de tamaño 40 de esta población y calcular la \(T\) correspondiente. Después, para cada población, miraremos la proporción de veces que la \(T\) ha dado menor o igual que el umbral \(L_0\), es decir, la proporción de veces que aceptaríamos la hipótesis nula \(\mu=2.5\) y que por lo tanto cometeríamos un error de tipo II. Organizamos todas estas proporciones en un vector que llamamos p.error.Tipo.II.
p.error.Tipo.II=rep(1,100)
for (j in 1:100){
Tes=replicate(200,estadístico(40,mus[j],sigma0))
p.error.Tipo.II[j]=length(which((Tes<=L0)==TRUE))/200
}
p.error.Tipo.II## [1] 0.015 0.275 0.055 0.005 0.495 0.040 0.000 0.005 0.420 0.090 0.000 0.085
## [13] 0.245 0.000 0.195 0.000 0.080 0.000 0.525 0.000 0.000 0.410 0.140 0.000
## [25] 0.000 0.330 0.050 0.000 0.010 0.610 0.460 0.575 0.000 0.000 0.005 0.000
## [37] 0.110 0.000 0.000 0.000 0.000 0.000 0.015 0.115 0.020 0.000 0.000 0.000
## [49] 0.040 0.015 0.000 0.005 0.000 0.000 0.045 0.190 0.000 0.005 0.560 0.085
## [61] 0.000 0.000 0.595 0.015 0.005 0.000 0.000 0.000 0.500 0.000 0.085 0.195
## [73] 0.370 0.645 0.015 0.000 0.245 0.130 0.140 0.590 0.315 0.325 0.000 0.105
## [85] 0.000 0.085 0.000 0.460 0.000 0.000 0.005 0.175 0.065 0.390 0.000 0.000
## [97] 0.010 0.000 0.000 0.000En algunos casos no hemos cometido ningún error de tipo II, y en otros, en más de la mitad de las veces. La proporción media de errores de tipo II ha sido:
## [1] 0.1179Si tomamos muestras más grandes, la probabilidad de error de tipo II disminuye. Comprobémoslo repitiendo este segundo experimento con muestras de tamaño 400.
p.error.Tipo.II.400=rep(1,100)
for (j in 1:100){
Tes=replicate(200,estadístico(400,mus[j],sigma0))
p.error.Tipo.II.400[j]=length(which((Tes<=L0)==TRUE))/200
}
mean(p.error.Tipo.II.400)## [1] 2e-04e significa “multiplica el número que me precede por 10 elevado al número que me sigue”. Así, 2e-04 significa \(2\times 10^{-4}\), o sea, 0.0002.
Multiplicando por 10 el tamaño de las muestras, hemos bajado de una tasa de errores de tipo II del 11.79% al 0.02%.
Recordad que la potencia de un contraste es la probabilidad de no cometer un error de tipo II. Hemos visto que tomando muestras más grandes, la proporción de errores de tipo II ha disminuido. Esto es general:
Volvemos a la situación general en la que tenemos una variable aleatoria \(X\) normal \(N(\mu,\sigma)\) y queremos comparar \(\mu\) con cierto valor \(\mu_0\) y supongamos que ahora buscamos evidencia de que \(\mu<\mu_0\), de manera que el contraste es \[ \left\{\begin{array}{l} H_{0}:\mu=\mu_0\\ H_{1}:\mu < \mu_0 \end{array} \right. \] En este caso, el p-valor es \(P(T\leqslant T_0)\) y, razonando exactamente igual que antes, obtenemos las dos reglas de rechazo equivalentes siguientes:
Rechazaremos \(H_0\) si \(T_0< t_{n-1,\alpha}\)
Rechazaremos \(H_0\) si el p-valor es menor que \(\alpha\)
¿Y qué pasa si ahora buscamos evidencia de que \(\mu\) es diferente de \(\mu_0\)? Es decir, si nos planteamos el contraste \[ \left\{\begin{array}{l} H_{0}:\mu=\mu_0\\ H_{1}:\mu\ \neq \mu_0 \end{array} \right. \]
En este caso, rechazaremos \(H_{0}\) cuando \(\overline{X}\) es muy diferente de \(\mu_0\) y esto lo traducimos en que rechazaremos \(H_{0}\) cuando el valor absoluto de \(T_0\), \(|T_0|\), sea mayor que un cierto umbral \(L_0\), que determinamos a partir de \(\alpha\) como antes:
\[ \begin{array}{l} \alpha = P(\text{Rechazar } H_{0}| H_{0} \text{ verdadera})=P(|T|> L_0)\\ \hphantom{\alpha} = P(T< -L_0\text{ o } T>L_0)= P(T< -L_0)+P(T>L_0)\\ \hphantom{\alpha} =2P(T>L_0) \text{ (por la simetría de $t_{n-1}$)}\\ \Longrightarrow \alpha/2=P(T>L_0)= 1-P(T\leqslant L_0) \\ \Longrightarrow P(T\leqslant L_0)=1-\alpha/2\Longrightarrow L_0= t_{n-1,1-\alpha/2} \end{array} \]
Por lo tanto, en un contraste bilateral con nivel de significación \(\alpha\), tenemos la regla de rechazo siguiente:
Rechazaremos \(H_0\) si \(|T_0|>t_{n-1,1-\alpha/2}\)
En este caso, el p-valor será la probabilidad de que \(T\) tome un valor tan o más extremo que \(T_0\) en el sentido de la hipótesis alternativa, es decir, más lejos de 0 que \(T_0\): mayor que \(|T_0|\) o menor que \(-|T_0|\): \[ \text{p-valor} =P(T\leqslant -|T_0|)+P(T\geqslant |T_0|)=2 P(T\geqslant |T_0|). \] Fijaos en que usamos que, por la simetría de las variables t de Student, \(P(T\leqslant -|T_0|)=P(T\geqslant |T_0|)\).
Por lo tanto, \[ \begin{array}{l} \text{Rechazamos $H_0$} \Longleftrightarrow |T_0|>t_{n-1,1-\alpha/2}\\ \qquad \Longleftrightarrow P(T\geqslant |T_0|)<{\alpha}/{2}\\ \qquad\Longleftrightarrow 2 P(T\geqslant |T_0|)<\alpha\\ \qquad \Longleftrightarrow \text{p-valor} < \alpha \end{array} \]
Así pues, en un contraste bilateral con nivel de significación \(\alpha\) también tenemos la regla de rechazo:
Rechazaremos \(H_0\) si el p-valor es menor que \(\alpha\)
En resumen, en un contraste de una media \(\mu\) usando un test t sobre una muestra de tamaño \(n\) y nivel de significación \(\alpha\):
Si \(H_1:\mu> \mu_0\):
- Rechazamos \(H_0\) si \(T_0>t_{n-1,1-\alpha}\)
- El p-valor es \(P(T\geqslant T_0)\)
- Rechazamos \(H_0\) si el p-valor es menor que \(\alpha\)
Si \(H_1:\mu< \mu_0\):
- Rechazamos \(H_0\) si \(T_0< t_{n-1,\alpha}\)
- El p-valor es \(P(T\leqslant T_0)\)
- Rechazamos \(H_0\) si el p-valor es menor que \(\alpha\)
Si \(H_1:\mu\neq \mu_0\):
- Rechazamos \(H_0\) si \(|T_0|>t_{n-1,1-\alpha/2}\)
- El p-valor es \(2P(T\geqslant |T_0|)\)
- Rechazamos \(H_0\) si el p-valor es menor que \(\alpha\)
Ejemplo 14.15 Sea \(X\) una variable poblacional normal. Queremos realizar el contraste \[ \left\{\begin{array}{l} H_{0}:\mu=20\\ H_{1}:\mu>20 \end{array} \right. \] con un nivel de significación de 0.05. Tomamos una muestra aleatoria simple de \(n=25\) observaciones y obtenemos \(\overline{x}=20.7\) y \(\widetilde{s}=1.8\). ¿Qué decidimos?
El estadístico de contraste que usaremos es \[ T=\dfrac{\overline{X}-\mu_0}{\widetilde{S}_X/\sqrt{n}} \] con \(\mu_0=20\) y \(n=25\).
Su valor en nuestra muestra es \[ T_0=\dfrac{20.7-20}{{1.8}/{\sqrt{25}}}=1.944 \]
El p-valor es \[ P(T\geqslant 1.944)=P(t_{24}\geqslant 1.944)=0.032 \]
Decisión: Como el p-valor es menor que 0.05, rechazamos \(H_0\) y concluimos (con \(\alpha=0.05\)) que \(\mu>20\). Es decir, hemos obtenido evidencia estadísticamente significativa de que \(\mu>20\).
Ejemplo 14.16 Sea \(X\) una variable poblacional normal. Queremos realizar el contraste \[ \left\{\begin{array}{l} H_{0}:\mu=20\\ H_{1}:\mu>20 \end{array} \right. \] con un nivel de significación de 0.01. Con la misma muestra aleatoria simple del ejemplo anterior, ¿qué decidimos?
El p-valor es el mismo que antes, 0.032, porque el contraste y la muestra son los mismos. Como este p-valor es mayor que 0.01, no podemos rechazar \(H_0\) con \(\alpha=0.01\) y tenemos que aceptar que \(\mu=20\). Con este nivel de significación, no hemos obtenido evidencia de que \(\mu>20\).
Ejemplo 14.17 Sea \(X\) una variable poblacional normal. Queremos realizar el contraste \[ \left\{\begin{array}{l} H_{0}:\mu=20\\ H_{1}:\mu< 20 \end{array} \right. \] con un nivel de significación de 0.05. Con la misma muestra aleatoria simple de los ejemplos anteriores (\(n=25\), \(\overline{x}=20.7\), \(\widetilde{s}=1.8\)), ¿qué decidimos?
El estadístico de contraste y su valor \(T_0\) son el mismos que antes.
p-valor \[ P(T\leqslant 1.944)=P(t_{24}\leqslant 1.944)=0.968 \]
Decisión: Como el p-valor es mayor que 0.05, no podemos rechazar \(H_0\) y tenemos que aceptar que \(\mu=20\). Es decir, no hemos obtenido evidencia estadísticamente significativa de que \(\mu<20\).
Ejemplo 14.18 Sea \(X\) una variable poblacional normal. Queremos realizar el contraste \[ \left\{\begin{array}{l} H_{0}:\mu=20\\ H_{1}:\mu\neq 20 \end{array} \right. \] con un nivel de significación de 0.05. Con la misma muestra aleatoria simple de los ejemplos anteriores, ¿qué decidimos?
Recordemos que \(n=25\), \(\overline{x}=20.7\) y \(\widetilde{s}=1.8\). El estadístico de contraste valía \(T_0=1.944\).
Ahora el p-valor es \[ 2\cdot P(T\geqslant 1.944)=2\cdot P(t_{24}\geqslant 1.944)=0.064 \]
Como el p-valor es mayor que \(\alpha\), no podemos rechazar \(H_0\): no podemos afirmar con \(\alpha=0.05\) que \(\mu\neq 20\). Es decir, no hemos obtenido evidencia estadísticamente significativa de que \(\mu\neq 20\).
Veamos, si hubiéramos demostrado que seguro que \(\mu> 20\), está claro que esto implicaría que \(\mu \neq 20\). Pero habíamos llegado a la conclusión de que \(\mu> 20\) asumiendo una cierta probabilidad de cometer un error de tipo I, y ahora nos preguntamos si podemos decidir que \(\mu \neq 20\) asumiendo el mismo riesgo de equivocarnos. En esta situación las reglas de la lógica aristotélica ya no funcionan.
Fijaos en que, en realidad, lo que pasa es que encontraríamos evidencia de que \(\mu \neq 20\) si \(T\) fuera muy grande o muy pequeño. Por lo tanto, en el contraste bilateral tenemos dos fuentes de error de tipo I: que por puro azar \(T\) nos salga muy grande o que nos salga muy pequeño. En cambio, solo encontraremos evidencia de que \(\mu> 20\) si \(T\) es muy grande, y por consiguiente en el contraste unilateral tenemos una sola fuente de error de tipo I. Entonces, para garantizar la misma probabilidad de error de tipo I, tenemos que ser mucho más exigentes en el contraste bilateral, donde nos podemos equivocar de dos maneras diferentes, que en el unilateral. Por eso es más fácil rechazar la hipótesis nula en un contraste unilateral que en uno bilateral.
Ejemplo 14.19 Sea \(X\) una variable poblacional normal. Queremos realizar el contraste \[ \left\{\begin{array}{l} H_{0}:\mu=20\\ H_{1}:\mu \neq 20 \end{array} \right. \] con un nivel de significación de 0.05. Tomamos una muestra aleatoria simple de \(n=25\) observaciones y obtenemos \(\overline{x}=19\) y \(\widetilde{s}=1.8\). ¿Qué decidimos?
El estadístico de contraste \[ T=\dfrac{\overline{X}-\mu_0}{\widetilde{S}_X/\sqrt{n}} \] ahora vale \[ T_0=\dfrac{19-20}{{1.8}/{\sqrt{25}}}=-2.778 \]
El p-valor es \[ 2P(T\geqslant -2.778)=P(t_{24}\geqslant -2.778)=1.99 \]
Decisión: como el p-valor es mayor que \(\alpha\), no podemos rechazar \(H_0\).
¡NO! El p-valor no es \(2\cdot P(T\geqslant T_0)\), sino \(2\cdot P(T\geqslant |T_0|)\). Por lo tanto, el p-valor es \[ 2\cdot P(T\geqslant 2.778)=2\cdot P(t_{24}\geqslant 2.778)=0.01 \] y como este p-valor es menor que \(\alpha\), podemos rechazar \(H_0\) y concluir, con nivel de significación 0.05, que \(\mu\neq 20\). Es decir, hemos obtenido evidencia estadísticamente significativa de que \(\mu\neq 20\).
14.6 La potencia de un contraste
Recordad que la potencia \(1-\beta\) es la probabilidad de rechazar \(H_0\) cuando \(H_1\) es verdadera.
Por ejemplo, en el ejemplo del calcio en diabéticos de la Sección 14.5, la regla de rechazo era \[ T=\frac{\overline{X}-2.5}{\widetilde{S}_X/\sqrt{n}}>1.685, \] por lo tanto la potencia era \[ 1-\beta=P(\text{Rechazar } H_0\,|\, H_1\text{ verdadera})=P(T>1.685\,|\, \mu>2.5). \] Esta probabilidad es imposible de calcular, pero hay programas que la saben estimar para los tests más usuales. Por ejemplo, el paquete pwr de R, el módulo jpower de JAMOVI o la aplicación G*Power que podéis descargar del url https://www.psychologie.hhu.de/arbeitsgruppen/allgemeine-psychologie-und-arbeitspsychologie/gpower.
Esta estimación de la potencia se basa en la idea siguiente. Para cada tipo de contraste se tiene una relación numérica entre:
La potencia
El tamaño de la muestra \(n\): la potencia crece con \(n\)
El nivel de significación \(\alpha\): la potencia decrece con \(\alpha\)
El tamaño del efecto, un valor que cuantifica la diferencia entre el parámetro muestral y el valor contrastado. La potencia crece con el valor absoluto del tamaño del efecto.
Esta relación permite calcular cualquiera de los cuatro valores a partir de los otros tres. Así, sabiendo \(n\), \(\alpha\) y el tamaño del efecto, podemos calcular la potencia del contraste efectuado.
La aplicación más importante de estos cálculos es la determinación del tamaño de la muestra necesario para la potencia deseada. Al planear un experimento para realizar un contraste, hay que:
Fijar el nivel de significación deseado
Fijar la potencia deseada
Estimar el tamaño del efecto esperado (a partir de nuestra teoría, de nuestra experiencia, de los resultados de otros estudios…).
y usar un programa adecuado que calcule el tamaño de la muestra necesario para lograr la potencia deseada a partir de estos valores.
Desconfiad de los trabajos donde esto no se haga. Podría ser que la potencia fuera muy baja y hubiera un sesgo de infrapotencia (underpower): se necesitaba un efecto muy grande para poder rechazar la hipótesis nula y publicar el artículo.
Por ejemplo, imaginad que en un estudio para determinar si la tasa de efectividad de un cierto tratamiento de una enfermedad es mayor del 90% se prueba sobre una muestra de solo 10 enfermos. Entonces, para obtener un p-valor inferior al 0.05 sería necesario que los 10 enfermos se curaran. Por lo tanto, lo más seguro es que los resultados de este estudio solo vieran la luz en un revista científica si la tasa observada de curación en la muestra fuera del 100%. Animado por esta tasa de curación perfecta, uno prueba el tratamiento y comprueba en sus pacientes que su eficacia queda lejos del 100%.14.7 Intervalo de confianza de un contraste
Repasemos los conceptos introducidos hasta ahora, y pongamos nombre a otros:
Nivel de significación, \(\alpha\): probabilidad de rechazar \(H_0\) si esta es verdadera (probabilidad de error de tipo I, de falso positivo).
Nivel de confianza, \(1-\alpha\): probabilidad de aceptar \(H_0\) si esta es verdadera (probabilidad de verdadero negativo).
Potencia, \(1-\beta\): probabilidad de rechazar \(H_0\) si \(H_1\) es verdadera (probabilidad de verdadero positivo).
Estadístico de contraste: el valor que calculamos sobre una muestra aleatoria simple para efectuar el contraste
Región crítica o de rechazo: el rango de valores del estadístico de contraste para los que rechazamos \(H_{0}\) con un nivel de significación \(\alpha\) dado.
Región de aceptación: el complementario de la región de rechazo, es decir, el rango de valores del estadístico de contraste para los que aceptamos \(H_{0}\) con un nivel de significación \(\alpha\) dado.
p-valor: la probabilidad de que, si \(H_0\) es verdadera, el estadístico de contraste tome sobre una muestra aleatoria simple del mismo tamaño que la nuestra un valor tan o más extremo (en el sentido de \(H_1\)) que el obtenido sobre nuestra muestra.
Rechazamos \(H_{0}\) con un nivel de significación \(\alpha\) si el p-valor es menor que \(\alpha\).
Ejemplo 14.20 Si realizamos un test t para efectuar un contraste \[ \left\{\begin{array}{l} H_{0}:\mu=\mu_0\\ H_{1}:\mu > \mu_0 \end{array} \right. \] rechazamos \(H_0\) con nivel de significación \(\alpha\) (o con nivel de confianza \(1-\alpha\)) cuando \[ T=\dfrac{\overline{X}-\mu_0}{{\widetilde{S}_X}/{\sqrt{n}}}>t_{n-1,1-\alpha} \]
Por lo tanto:
Estadístico de contraste: este \(T\)
Región crítica para el nivel de significación \(\alpha\): el intervalo \((t_{n-1,1-\alpha},\infty)\)
Región de aceptación para el nivel de significación \(\alpha\): el intervalo \((-\infty,t_{n-1,1-\alpha}]\)
p-valor: \(P(T\geqslant T_0)\), donde \(T_0\) denota el valor de \(T\) en nuestra muestra
Si en cambio el contraste que queremos efectuar es \[ \left\{\begin{array}{l} H_{0}:\mu=\mu_0\\ H_{1}:\mu < \mu_0 \end{array} \right. \] rechazamos \(H_0\) con nivel de significación \(\alpha\) (o con nivel de confianza \(1-\alpha\)) cuando \[ T=\dfrac{\overline{X}-\mu_0}{{\widetilde{S}_X}/{\sqrt{n}}}<t_{n-1,\alpha} \]
Por lo tanto:
Estadístico de contraste: el mismo \(T\) que antes
Región crítica para el nivel de significación \(\alpha\): el intervalo \((-\infty,t_{n-1,\alpha})\)
Región de aceptación para el nivel de significación \(\alpha\): el intervalo \([t_{n-1,\alpha},\infty)\)
p-valor: \(P(T\leqslant T_0)\)
Finalmente, si el contraste que queremos realizar es \[ \left\{\begin{array}{l} H_{0}:\mu=\mu_0\\ H_{1}:\mu \neq \mu_0 \end{array} \right. \] rechazamos \(H_0\) con nivel de significación \(\alpha\) (o con nivel de confianza \(1-\alpha\)) cuando \[ |T|=\left|\dfrac{\overline{X}-\mu_0}{{\widetilde{S}_X}/{\sqrt{n}}}\right|>t_{n-1,1-\alpha/2} \] Por lo tanto:
Estadístico de contraste: el mismo \(T\) que antes
Región crítica para el nivel de significación \(\alpha\): la unión de intervalos \((-\infty,-t_{n-1,1-\alpha/2})\cup (t_{n-1,1-\alpha/2},\infty)\)
Región de aceptación para el nivel de significación \(\alpha\): el intervalo \([-t_{n-1,1-\alpha/2},t_{n-1,1-\alpha/2}]\)
p-valor: \(2P(T\geqslant |T_0|)\)
El intervalo de confianza de nivel de confianza \(1-\alpha\) de un contraste es un intervalo que tiene una probabilidad \(1-\alpha\) de contener el parámetro poblacional que contrastamos, en el sentido de los intervalos de confianza del tema anterior: se calcula con una fórmula que en un \((1-\alpha)\cdot 100\%\) de las veces que se aplica a una muestra aleatoria simple, produce un intervalo que contiene el parámetro poblacional.
El intervalo de confianza de un contraste se obtiene imponiendo que el estadístico de contraste pertenezca a la región de aceptación para el nivel de significación \(\alpha\) y despejando el parámetro poblacional.
Por ejemplo, consideremos el caso de un test t para efectuar un contraste \[ \left\{\begin{array}{l} H_{0}:\mu=\mu_0\\ H_{1}:\mu > \mu_0 \end{array} \right. \] Aceptamos \(H_0\) con nivel de significación \(\alpha\) cuando \[ \dfrac{\overline{X}-\mu_0}{{\widetilde{S}_X}/{\sqrt{n}}}\leqslant t_{n-1,1-\alpha} \] Despejando \(\mu_0\), obtenemos \[ \overline{X}- t_{n-1,1-\alpha}\cdot \dfrac{\widetilde{S}_X}{\sqrt{n}}\leqslant \mu_0 \] Por lo tanto, el intervalo de confianza de nivel de confianza \(1-\alpha\) para este contraste es \[ \Bigg[\overline{X}- t_{n-1,1-\alpha}\cdot \dfrac{\widetilde{S}_X}{\sqrt{n}},\infty\Bigg) \] Si la \(\mu_0\) que contrastamos pertenece a este intervalo, no podemos concluir que la \(\mu\) poblacional sea mayor que \(\mu_0\), y por lo tanto no podemos rechazar que \(\mu=\mu_0\).
En el ejemplo de los diabéticos de la Sección 14.5, da el intervalo \[ \Bigg[3.2- 1.73\cdot \dfrac{1.5}{\sqrt{20}},\infty\Bigg)=[2.62,\infty) \]
Concluimos que, con un nivel de confianza del 95%, la concentración media de calcio en sangre en los jóvenes diabéticos es como mínimo 2.62, y que por lo tanto, con este nivel de confianza, no puede ser 2.5, aunque por poco.
Si efectuamos un contraste bilateral con un test t \[ \left\{\begin{array}{l} H_{0}:\mu=\mu_0\\ H_{1}:\mu \neq \mu_0 \end{array} \right. \] aceptamos \(H_0\) con nivel de significación \(\alpha\) cuando \[ -t_{n-1,1-\alpha/2}\leqslant \dfrac{\overline{X}-\mu_0}{{\widetilde{S}_X}/{\sqrt{n}}}\leqslant t_{n-1,1-\alpha/2} \] Despejando \(\mu_0\), obtenemos: \[ \overline{X}- t_{n-1,1-\alpha/2}\cdot \dfrac{\widetilde{S}_X}{\sqrt{n}}\leqslant \mu_0 \leqslant \overline{X}+ t_{n-1,1-\alpha/2}\cdot \dfrac{\widetilde{S}_X}{\sqrt{n}} \] Por lo tanto, el intervalo de confianza de nivel de confianza \(1-\alpha\) para este contraste es \[ \Bigg[\overline{X}- t_{n-1,1-\alpha/2}\cdot \dfrac{\widetilde{S}_X}{\sqrt{n}},\overline{X}+ t_{n-1,1-\alpha/2}\cdot \dfrac{\widetilde{S}_X}{\sqrt{n}}\Bigg] \] ¿Os suena? Llamando \(q\) a \(1-\alpha\), de manera que \[ 1-\frac{\alpha}{2}=1-\frac{1-q}{2}=\frac{1+q}{2}, \] da \[ \Bigg[\overline{X}- t_{n-1,(1+q)/2}\cdot \dfrac{\widetilde{S}_X}{\sqrt{n}},\overline{X}+ t_{n-1,(1+q)/2}\cdot \dfrac{\widetilde{S}_X}{\sqrt{n}}\Bigg] \]
Es el intervalo de confianza para \(\mu\) basado en la t de Student que vimos en el tema anterior.
En resumen, dado un contraste de hipótesis, podemos decidir si rechazamos \(H_0\) en favor de \(H_1\) con nivel de significación \(\alpha\) usando:
La región crítica: Si el estadístico de contraste cae dentro de la región crítica para el nivel de significación \(\alpha\), rechazamos \(H_0\).
El p-valor: Si el p-valor es menor que el nivel de significación \(\alpha\), rechazamos \(H_0\).
El intervalo de confianza: Si el valor que contrastamos del parámetro poblacional no pertenece al intervalo de confianza de nivel de confianza \(1-\alpha\), rechazamos \(H_0\).
En la práctica no se usa la región crítica: su papel se reduce a ser un paso intermedio en la obtención de las otras dos reglas de rechazo. Por otro lado, el uso del p-valor es muy discutido porque da lugar a falsas interpretaciones (la probabilidad de que la hipótesis nula sea verdadera; un valor a comparar con el umbral absoluto 0.05 sin tener nada más en consideración; …), pero bien entendido (como una medida de la consistencia de lo observado con la hipótesis nula) es útil.
Lo más adecuado es dar el p-valor y el intervalo de confianza:
- El p-valor, porque aun es lo que todo el mundo espera y para que el lector lo pueda comparar con el nivel de significación que considere oportuno.
- El intervalo de confianza, porque muestra el margen con el cual hemos aceptado o rechazado la hipótesis nula con nuestro nivel de significación.
Si no establecemos un nivel de significación \(\alpha\), lo habitual es:
Aceptar \(H_0\) si el p-valor es mayor que 0.1: se dice que el p-valor no es estadísticamente significativo
Rechazar \(H_0\) si el p-valor es menor que 0.05: se dice que el p-valor es estadísticamente significativo
Si el p-valor está entre 0.05 y 0.1 y no se ha fijado nivel de significación, lo mejor que podéis hacer es no concluir nada y decir que es necesario repetir el estudio con una muestra mayor.
Cuando el p-valor es menor que 0.05, se suelen distinguir tres franjas:
- Significativo si está entre 0.01 y 0.05
- Fuertemente significativo si está entre 0.001 y 0.01
- Muy significativo si es menor que 0.001
Normalmente estas franjas se indican con un código de asteriscos:
Un asterisco, *, para los p-valores entre 0.01 y 0.05
Dos asteriscos, **, para los p-valores entre 0.001 y 0.01
Tres asteriscos, ***, para los p-valores por debajo de 0.001
Aunque hay otras propuestas:

Figura 14.3: “P-values” (https://xkcd.com/1478/ (CC-BI-NC 2.5))
Dado que rechazamos \(H_0\) si, y solo si, el p-valor es menor que \(\alpha\), el p-valor de un contraste es el nivel de significación más pequeño para el cual rechazaríamos la hipótesis nula. Es decir:
Por lo tanto, por favor, acostumbraos a dar el p-valor, y no la franja de significación donde cae.
14.8 Ajuste de p-valores
Si efectuamos \(M\) contrastes independientes usando una regla de decisión que garantice un nivel de significación \(\alpha\) dado, y en todos ellos la \(H_0\) es verdadera, el número de contrastes donde nos equivocaremos y rechazaremos \(H_0\) tiene distribución binomial \(B(M,\alpha)\). En particular, esperamos cometer \(\alpha M\) errores de tipo I, y la probabilidad de cometer alguno es \(1-(1-\alpha)^M\). Este valor es mayor que \(\alpha\). Por ejemplo, si realizamos 3 contrastes con nivel de significación \(\alpha =0.05\) y en los tres la hipótesis nula es vertadera, la probabilidad de que cometamos algún Error de Tipo I es \(1-(1-0.05)^{3} \approx 0.14\).

Figura 14.4: “Significant” (https://xkcd.com/882/ (CC-BI-NC 2.5))
Si queremos mantener un nivel de significación global \(\alpha\), es decir, que la probabilidad de cometer algún error de tipo I sea \(\alpha\), hay que reducir el nivel de significación de cada uno de ellos, o equivalentemente aumentar (ajustar) el p-valor de cada contraste y comparar el valor ajustado con el \(\alpha\) fijado.
Se han propuesto muchos métodos para ajustar los p-valores de grupos de contrastes. El más sencillo, y el más popular, es el de Bonferroni. Su idea es que, usando la aproximación \(1-(1-x)^M \approx M\cdot x\), para efectuar \(M\) contrastes con un nivel de significación global \(\alpha\):
tenemos que realizar cada contraste con nivel de significación \(\alpha/M\) (y así el nivel de significación global será \(\approx\) \(M\cdot \alpha/M=\alpha\))
o equivalentemente:
tenemos que multiplicar el p-valor de cada contraste por \(M\) antes de compararlo con el nivel de significación \(\alpha\).
Ambos métodos son equivalentes, porque \[ p< \alpha/M\Longleftrightarrow M\cdot p<\alpha \]
Por ejemplo, si realizamos 3 contrastes, para obtener un nivel de significación global \(\alpha =0.05\) el método de Bonferroni nos dice que tenemos que multiplicar cada p-valor por 3 y comparar los p-valores ajustados resultantes con 0.05.
14.9 Resultados estadísticamente significativos versus resultados clínicamente significativos
Que en un contraste obtengamos un valor estadísticamente significativo quiere decir que es muy improbable que el valor del estadístico se obtenga por pura casualidad si la hipótesis nula es verdadera, y que es más verosímil que en la realidad sea la hipótesis alternativa la verdadera. Pero que un resultado sea estadísticamente significativo puede deberse a una diferencia muy pequeña en una muestra muy grande. Y esta diferencia tan pequeña puede que no sea clínicamente relevante.

Figura 14.5: Estadísticamente significativo no significa clínicamente relevante.
Por ejemplo, imaginad que queremos estudiar si una vacuna para una determinada enfermedad es efectiva. Tomamos dos grupos de personas, vacunamos las de un grupo, dejamos sin vacunar las del otro, esperamos un tiempo prudencial, y contamos cuántos han enfermado en cada grupo. Fijemos el nivel de significación usual \(\alpha=0.05\) y supongamos que obtenemos un p-valor por debajo de 0.05. ¡Gran júbilo! Hemos obtenido evidencia estadísticamente significativa de que nuestra vacuna funciona. Una diferencia entre las proporciones de enfermos en el grupo de control y el grupo de vacunados como la que hemos encontrado sería muy improbable si la vacuna no fuera efectiva.
Pero a este p-valor pequeño podemos llegar de muchas maneras. Por ejemplo:
Puede que hayamos tomado 100 sujetos en cada grupo y que hayan enfermado 20 controles, un 20%, y 10 vacunados, un 10% (el p-valor del test aproximado de dos proporciones que explicaremos en el próximo tema es, con estos valores, 0.024). En este caso podríamos considerar el resultado no solo estadísticamente significativo, sino clínicamente relevante: en nuestro experimento, la vacuna ha reducido a la mitad el riesgo de contraer la enfermedad, 10 puntos porcentuales en términos absolutos.
Podríamos haber tomado 100000 sujetos en cada grupo y que hayan enfermado 20000 controles, un 20%, y 19600 vacunados, un 19.6% (el p-valor del test aproximado que hemos mencionado antes es, con estos valores, 0.0126). En este caso el resultado sigue siendo estadísticamente significativo, incluso más que antes, porque el p-valor es más pequeño, pero la relevancia clínica ya no está tan clara: estimamos que la vacuna reduce en un 2% el riesgo de contraer la enfermedad, en términos absolutos 4 décimas de punto porcentual.
En el segundo caso, con una muestra tan grande, la potencia era muy grande y como consecuencia cualquier pequeña diferencia se convertía en estadísticamente significativa, aunque fuera eso, pequeña.
En este curso nos preocupamos sobre todo del significado estadístico del resultado de un estudio, que medimos con el p-valor. Más adelante en vuestra vida profesional, el significado clínico lo tendréis que decidir vosotros a partir de vuestra experiencia.
Y tened en cuenta que un resultado publicado puede ser estadísticamente significativo y no significar nada. Por ejemplo, el paquete statcheck de R permite revisar de manera automática todos los cálculos de un artículo escrito en un formato concreto usado en revistas de psicología y comprobar los p-valores. Los autores del paquete analizaron 30,000 artículos y concluyeron que:
“Hemos encontrado que la mitad de los artículos contienen al menos un p-valor erróneo. Y uno de cada ocho artículos contiene un p-valor erróneo que además afecta la conclusión estadística.”
Por lo tanto,
- Cualquier artículo puede dar un p-valor pequeño que esté equivocado
No os fiéis de los resultados. Si las conclusiones os interesan, revisad los cálculos.
Además, tened presente que:
Cualquier estudio mal diseñado o mal realizado puede dar un p-valor pequeño… que no signifique absolutamente nada.
Si las conclusiones de un artículo os interesan, revisad si el estudio ha sido bien diseñado, ejecutado y analizado.
Cualquier estudio perfectamente diseñado y realizado puede dar por puro azar un p-valor pequeño… que implique un falso positivo.
Contra esto último no podemos hacer nada, salvo ser escépticos.
Ejemplo 14.21 En un artículo publicado en 2010 se obtuvo evidencia de que una persona que fuera Aries, Tauro, Géminis, Leo, Escorpio o Capricornio tenía una mayor probabilidad de supervivencia a 5 años vista tras un alotransplante de células madre para tratar una leucemia mieloide crónica que una persona de fuera de los otros signos del zodíaco (58% de tasa de supervivencia frente a un 48%, p-valor 0.007). ¿Nos lo tenemos a creer? Spoiler: El subtítulo del artículo es An artificial association.
14.10 Test
(1) Cuando escribimos formalmente un contraste de hipótesis, ¿qué es \(H_1\)?
- Es la primera hipótesis que hacemos y que después ya modificaremos en función de los datos obtenidos
- Es la hipótesis nula
- Es la hipótesis alternativa
- Es la variable haleatoria poblacional de interés
- Ninguna de las otras respuestas es la correcta
(2) Un test de COVID-19 no es nada más que un contraste de hipótesis: tomas una muestra del individuo y decides si tiene COVID-19 o no. ¿Qué contraste es?
- H0: El individuo tiene COVID-19; H1: El individuo no tiene COVID-19
- H0: El individuo no tiene COVID-19; H1: El individuo tiene COVID-19
- H0: El individuo no tiene COVID-19; H1: El individuo podría tener COVID-19
- H0: No sé si el individuo tiene COVID-19; H1: El individuo tiene COVID-19
(3) Un científico publica un artículo donde afirma que las personas que toman un determinado medicamento tienen una mayor probabilidad de formación de cálculos renales. Más tarde se descubre que en realidad esta asociación no existe. ¿Qué tipo de error cometió el científico y por qué?
- Tipo I, porque afirmó que la hipótesis nula es cierta cuando en realidad es falsa.
- Tipo I, porque afirmó que la hipótesis nula es falsa cuando en realidad es cierta.
- Tipo II, porque afirmó que la hipótesis nula es cierta cuando en realidad es falsa.
- Tipo II, porque afirmó que la hipótesis nula es falsa cuando en realidad es cierta.
(4) En un examen considerado como un contraste (marca todas las respuestas correctas):
- Que el estudiante apruebe sin saber la materia es un error de tipo I
- Que el estudiante apruebe sin saber la materia es un error de tipo II
- Que el estudiante apruebe sin saber la materia es simultáneamente un error de tipo I y de tipo II
- El nivel de significación es la probabilidad de que el estudiante apruebe sin saber la materia
- El nivel de significación es la probabilidad de que el estudiante suspenda si no sabe la materia
(5) ¿Qué significa que en un contraste de hipótesis tomemos un nivel de significación del 1%? Marca la respuesta correcta:
- Que un 1% de las veces que la hipótesis nula sea falsa la rechazaremos en favor de la alternativa.
- Que un 1% de las veces que la hipótesis nula sea falsa la aceptaremos.
- Que un 1% de las veces que la hipótesis nula sea verdadera la rechazaremos en favor de la alternativa.
- Que un 1% de las veces que la hipótesis nula sea verdadera la aceptaremos.
- Que un 1% de las veces rechazaremos la hipótesis nula.
- Que un 1% de las veces aceptaremos la hipótesis nula.
- Todas las otras respuestas son incorrectas.
(6) Al analizar los resultados de un ensayo clínico, se concluye que las tasas de curación de los dos tratamientos estudiados son diferentes, con un p-valor de 0.034. Esto significa (marca todas las respuestas correctas):
- Que hay un 3.4% de probabilidad de que, si se repite el estudio, no se encuentren diferencias significativas.
- Que hay un 3.4% de probabilidad de que la tasa de curación de los tratamientos estudiados sean iguales.
- Que hay un 3.4% de diferencia, o más, en las tasas de curación de los tratamientos estudiados.
- Que ha habido un 3.4% de diferencia, o más, en las tasas de curación de los tratamientos en nuestras muestras.
- Que hay un 3.4% de probabilidad de que la diferencia obtenida entre las tasas de curación, o una aún mayor, se obtenga por pura casualidad.
- Todas las otras respuestas son incorrectas.
(7) En un pequeño ensayo aleatorio simple ciego de un nuevo tratamiento en pacientes con infarto de miocardio agudo, la mortalidad en el grupo tratado fue la mitad que en el grupo control, pero la diferencia no resultó estadísticamente significativa. Podemos concluir que (marca todas las respuestas correctas):
- Como la diferencia no es estadísticamente significativa, el tratamiento es inútil.
- Podría ser que el contraste tuviera poca potencia, y por eso la diferencia detectada no ha sido estadísticamente significativa.
- La reducción observada de la mortalidad es tan grande que deberíamos introducir el tratamiento inmediatamente, aunque dicha reducción no sea estadísticamente significativa.
- Esto se debe a que el ensayo fue simple ciego, y no doble ciego.
- Es conveniente llevar a cabo un nuevo ensayo sobre una muestra de pacientes de mayor tamaño.
- Todas las otras respuestas son incorrectas.
(8) En un estudio donde se contrastó si los individuos con hipertensión arterial tienen un mayor riesgo de sufrir un infarto de miocardio que los individuos normotensos, se obtuvo un p-valor de 0.02. ¿Qué quiere decir esto? (Marca una sola respuesta.)
- La probabilidad de que los hipertensos tengan más riesgo de sufrir un infarto de miocardio que los normotensos es 0.02
- La probabilidad de que los hipertensos tengan más riesgo de sufrir un infarto de miocardio que los normotensos es 0.98
- Un hipertenso tiene una probabilidad de sufrir un infarto de miocardio un 2% mayor que un normotenso.
- En las muestras que hemos usado en el estudio, la proporción de hipertensos que han sufrido un infarto de miocardio es un 2% mayor que la de normotensos que han sufrido un infarto de miocardio
- Ninguna de las otras respuestas es correcta.
(9) En un estudio sobre lactancia materna e inteligencia, a 300 niños que fueron muy pequeños al nacer se les dio la leche materna de su madre o leche infantil, a elección de la madre. A la edad de 8 años, se midió el CI (cociente intelectual) de estos niños. El CI medio en el grupo de leche infantil fue 92.8, en comparación con un CI medio de 103.0 en el grupo de leche materna. La diferencia fue estadísticamente significativa, con un p-valor inferior a 0.001. Marca todas las afirmaciones correctas:
- Hay evidencia estadísticamente significativa de que la alimentación mediante leche infantil de los bebés muy pequeños reduce su CI a los 8 años.
- Hay evidencia estadísticamente significativa de que elegir alimentar un bebé muy pequeño con leche materna aumenta el CI del niño a los 8 años.
- Hay evidencia estadísticamente significativa de que el tipo de leche no tiene ningún efecto en el CI subsecuente.
- La probabilidad de que el tipo de leche no afecte al CI subsiguiente es inferior al 0.1%.
- Si la elección del tipo de leche influyera en el CI, la probabilidad de que la diferencia observada del CI medio en el grupo de leche materna menos el del grupo de leche infantil fuera la de este estudio, o menor, es menor que 0.001.
- Todas las otras respuestas son incorrectas.
(10) En un contraste de hipótesis, si la hipótesis alternativa es verdadera pero se acepta la hipótesis nula (marca todas las conclusiones correctas, hay al menos una):
- Se comete un error de tipo I.
- Se comete un error de tipo II.
- La potencia disminuye.
- El p-valor es mayor que el nivel de significación.
- El p-valor es menor que el nivel de significación.
(11) Siempre que en un contraste de hipótesis NO se rechaza la hipótesis nula, ¿cuál o cuáles de las siguientes afirmaciones son correctas?
- Se ha demostrado que la hipótesis nula es verdadera.
- Se ha demostrado que la hipótesis alternativa es falsa.
- Se ha encontrado evidencia de que la hipótesis nula es verdadera
- Se ha encontrado evidencia de que la hipótesis alternativa es falsa
- Ninguna de las otras afirmaciones es verdadera.
(12) Si en un contraste de hipótesis tomamos un nivel de significación del 10% y una potencia del 60% y obtenemos un p-valor de 0.28, ¿cuál de las afirmaciones siguientes es verdadera?
- Aceptamos la hipótesis nula porque 0.28>0.1.
- Aceptamos la hipótesis nula porque 0.28<0.6.
- Rechazamos la hipótesis nula porque 0.28>0.1.
- Rechazamos la hipótesis nula porque 0.28<0.6.
- Con los datos dados, no tenemos criterio para aceptar o rechazar la hipótesis nula.
(13) En un estudio se trató con un suplemento dietético más dieta a 39 insuficientes renales y solamente con dieta a 40, de manera que los pacientes conocían qué tratamiento recibieron. Se compararon 20 variables entre ambos grupos y en una comparación se encontró una diferencia a favor del suplemento estadísticamente significativa con un nivel de significación del 5% (p-valor 0.000021). ¿Cómo interpretas estos resultados? Marca una sola respuesta.
- El estudio no permite concluir nada, ya que si realizamos 20 contrastes con un nivel de significación del 5%, esperamos que alguno dé un resultado estadísticamente significativo aunque no haya diferencia entre los tratamientos
- El p-valor tan pequeño descarta la posibilidad de un falso positivo en el caso en que se ha encontrado una diferencia estadísticamente significativa
- El hecho de haber encontrado una diferencia estadísticamente significativa en una comparación puede deberse a un error de tipo II
- Con unas muestras de pacientes tan pequeñas, la potencia de los contrastes seguramente es muy baja, lo que explica que hayamos obtenido algún resultado estadísticamente significativo
- Como en un 5% (el nivel de significación) de los contrastes se obtuvo un resultado favorable a favor del suplemento dietético, concluimos que su introducción es eficaz
(14) En un contraste que hemos llevado a cabo con nivel de significación 0.05 hemos obtenido un p-valor de 1.8. ¿Cuál ha de ser nuestra decisión?
- Aceptar la hipótesis nula, porque el p-valor es mayor que el nivel de significación.
- Rechazar la hipótesis nula, porque el p-valor es tan raro que hace inverosímil que la hipótesis nula sea verdadera.
- Revisar los cálculos, a ver dónde nos hemos equivocado.
- Ninguna de las otras respuestas es correcta.
(15) En un contraste con \(\alpha=0.05\) rechazamos la hipótesis nula. ¿Qué pasaría si, con la misma muestra, tomáramos \(\alpha=0.1\)?
- Seguro que también rechazaríamos la hipótesis nula
- Seguro que no rechazaríamos la hipótesis nula
- Puede pasar cualquier cosa
(16) En un contraste con \(\alpha=0.05\) no rechazamos la hipótesis nula. ¿Qué pasaría si, con la misma muestra, tomáramos \(\alpha=0.1\)?
- Seguro que tampoco rechazaríamos la hipótesis nula
- Seguro que sí que rechazaríamos la hipótesis nula
- Puede pasar cualquier cosa
(17) En un contraste de una media usando un test t, el aumento del tamaño de la muestra (marca todas las respuestas correctas):
- Mejora la aproximación del estadístico de contraste a una distribución normal.
- Esperamos que disminuya la probabilidad de error de tipo I.
- Esperamos que disminuya la probabilidad de error de tipo II.
- Esperamos que disminuya la potencia del contraste.
- Hace menos probable que la hipótesis nula sea verdadera.
- Todas las otras respuestas son incorrectas.
(18) En un contraste de hipótesis en el que la hipótesis nula es verdadera (marca una sola respuesta):
- Solo podemos cometer un error de tipo I.
- Solo podemos cometer un error de tipo II.
- Podemos cometer tanto un error de tipo I como un error de tipo II, pero no los dos.
- Podemos cometer tanto un error de tipo I como un error de tipo II, y podemos cometerlos los dos simultáneamente.
- Como la hipótesis nula es verdadera, no podemos cometer ni un error de tipo I ni un error de tipo II.
- Todas las otras respuestas son falsas.
(19) ¿Qué es la región de aceptación de un contraste sobre un parámetro poblacional?
- El conjunto de los valores del parámetro poblacional para los que tenemos que aceptar la hipótesis nula
- El conjunto de los valores del parámetro poblacional para los que tenemos que aceptar la hipótesis alternativa
- El conjunto de los valores del estadístico de contraste para los que tenemos que aceptar la hipótesis nula
- El conjunto de los valores del estadístico de contraste para los que tenemos que aceptar la hipótesis alternativa
- El conjunto de las estimaciones aceptables del parámetro poblacional a partir de la muestra
(20) Si efectuamos un mismo contraste con el mismo nivel de significación dos veces con dos muestras diferentes del mismo tamaño (marca las continuaciones correctas):
- La región de aceptación del contraste será las dos veces la misma
- La región de aceptación del contraste puede dar diferente con cada muestra
- El intervalo de confianza del contraste será las dos veces el mismo
- El intervalo de confianza del contraste puede dar diferente con cada muestra
(21) En un contraste de hipótesis hemos rechazado la hipótesis nula en favor de la alternativa con nivel de significación del 10%. El contraste ha tenido una potencia del 60%. ¿Cuál o cuáles de las afirmaciones siguientes son correctas en esta situación?
- La probabilidad que la hipótesis nula sea verdadera es 0.1
- La probabilidad que la hipótesis nula sea verdadera es 0.4
- La probabilidad que la hipótesis alternativa sea verdadera es 0.1
- La probabilidad que la hipótesis alternativa sea verdadera es 0.4
- Ninguna de las otras respuestas es correcta.
(22) Hemos efectuado el mismo contraste con dos muestras: con la primera hemos obtenido un p-valor de 0.1 y con la segunda un p-valor de 0.01. ¿Cuál o cuáles de las afirmaciones siguientes son correctas?
- Es más probable que sea verdadera la hipótesis nula del contraste con la primera muestra que la hipótesis nula del contraste con la segunda muestra
- Es más probable que sea verdadera la hipótesis nula del contraste con la segunda muestra que la hipótesis nula del contraste con la primera muestra
- No hay manera de saber si la hipótesis nula del contraste con la primera muestra es más probable o menos probable que la hipótesis nula del contraste con la segunda muestra
- Ninguna de las otras respuestas es correcta
(23) Hemos efectuado un test t de una media, con hipótesis alternativa \(\mu\neq 2\). ¿Es posible que hayamos obtenido (con la misma muestra) un intervalo de confianza del contraste del 95% [2.1,3.2] y un p-valor 0.13?
- Sí
- No
(24) Hemos efectuado un test t de una media, con hipótesis alternativa \(\mu\neq 2\). ¿Es posible que hayamos obtenido (con la misma muestra) un intervalo de confianza del contraste del 95% [1.8,3.2] y un p-valor 0.13?
- Sí
- No
(25) Hemos efectuado un test t de una media, con hipótesis alternativa \(\mu<2\). ¿Es posible que hayamos obtenido (con la misma muestra) un intervalo de confianza del contraste del 95% [1.8,3.2] y un p-valor 0.13?
- Sí
- No
(26) Hemos efectuado dos veces, con dos muestras diferentes, un mismo test t de una media, con hipótesis alternativa \(\mu\neq 2\). ¿Es posible que con una muestra hayamos obtenido un intervalo de confianza del contraste del 95% [2.1,3.2] y con la otra muestra un p-valor 0.13?
- Sí
- No